Negative Result: Improving Fixed Vocab Text Representations
Contemporary NLP research is primarily focused on large models and improving performance on increasingly diverse/complex tasks. Sometimes a lighter weight tool that performs a specific task quickly & cheaply is what’s needed. This post explores a failed attempt at improving lightweight text classification models and representations.
Context
At work I’ve been pretraining domain specific language models for use in downstream tasks. There are multiple steps to pretraining domain specific models, one being curation of a pretraining corpus. If your domain has limited data or you can’t use it for pretraining you might think you are out of luck. The domain of text I primarily work with, compliance data,falls into both categories. This leaves two options
- Synthetic data
- Large scale web filtering
While both could work for my use case, I opted for option 2. This involves filtering or sampling a relevant web scrape. For a larger web scrape like HuggingFace’s FineWeb, there are ~23B documents. Realistically the approach needs to be able to process 50K records per second. At this rate the process would still take 5 days.
There are papers on domain specific document selection, but for reasons outside the scope of this post I decided to use a classifier on top of a feature hashing model. This approach can filter large amounts of data in a simple, fast, and maintainable way. While filtering with feature hashes works well, collisions in the feature hashing vector leads to false positives. While additional training can be used to help minimize this issue, the underlying textual representation is the issue. That makes improving the feature hash’s output to minimize harmful collisions and favoring “good” collisions seem like a more promising approaching.
The Idea
Feature hashing creates an output similar to counting the occurrences of words in an instance. Unlike other count-based approaches, feature hashing models have no vocabulary. Instead they use hash functions to create indices for each word. The process involves 1. Tokenizing the input text 2. Running a hash over each word, taking the return number modulo the number of features (kind of like vocab size) desired, converting each word into an index 3. Creating a count vector from these indices (normalization is optional) 4. Running that count vector (feature) through a downstream model
Hashes can map different values to the same index. Two or more words having the same index is known as a “collision”. As noted in the intro collisions can lead to misclassifications, but they aren’t necessarily a bad thing. In static embeddings like Word2Vec synonymy is often captured and synonymy appears to help performance. Synonymy isn’t typically accounted for in count based approaches, but it could be. The idea is that by tweaking hash settings, we can
- optimize for “good” collisions, i.e., having synonyms sharing the same index
- minimize the number of distinct words colliding
The Rub
Turns out defining how “similar” a hashes output is to a cluster is more complicated than I thought. I’ve tried different classification metrics, including some adapted for clustering like Fowkles-Mallow. Subjectively speaking none work as well as I would like. Currently I’m using a hand crafted metric and while that seems better, searching through the variables (seed values, hash size, hash functions) is painstakingly slow. Moreover if the metric I picked isn’t correlated to downstream performance, is that because I picked a poor metric? Is it because the idea is flawed? Who knows..
For this reason, I decided to use a vocab based approach. This solves the issues associated to finding a good hash and lets me test the importance of synonymy in isolation. All I need to do is use the cluster output to assign words to an index. If this works, it opens the door to tackling the problem with feature hashing which was my original goal.
Experiment
The experiment has 6 steps, each a subsection below. These experiments were run on a laptop, i.e., limited computational resources. Any shortcuts taken, such as sampling, stem from that. The code can be found here.
Step 1. Selecting a Pretraining Corpus
The corpus used was wiki-english-20171001, sampling just the first 300k documents. This size is the largest I could comfortably fit and RAM and still run the following steps.
The tokenizer used was the one provided by Gensim. Words were lower cased. After tokenization all unique uni-grams and bi-grams were counted. The 1 million most common n-grams were kept.
Step 2. Training an Embedding
The pretraining corpus, wiki-english-20171001, was used to train a 50 dimensional FastText model using GenSim. FastText was chosen since it can handle OOV. I couldn’t get the pretrained FastText models I found to interpolate UNKs, so I decided to train one.
Step 3. Clustering to Find Synonyms
Each of the 1 million most common n-grams were embedded. These embedding were then clustered using DBSCAN. The settings used were: cosine as the distance metric;a min sample of 1; eps to 0.02 (equivalent to a minimum cosine similarity of 0.98).
After clustering we got about 850k clustered labels. Subjectively they look decent, synonym wise. No doubt they could be better, but as a first attempt I’ll take it. Below is a random sample of 10 groupings
[['minor alterations', 'major alterations'],
['operations in', 'the operation', 'in operation', 'operation of', 'of operation', 'operations and', 'operation in', 'co operation', 'operations of', 'operations the',
'operation and', 'operation the', 'operations on', 'operations to', 'and operation', 'operation was', 'an operation', 'operation on', 'operation to', 'operations for',
'operation is', 'operations at', 'for operation', 'operations are', 'operation with', 'operations with', 'operation at', 'operations as', 'operational in',
'operation for', 's operation', 'operation as', 'operations by', 'operation by', 'operational and', 'as operation', 'operation a', 'operations a', 'to operation', 'operations it',
'operation it', 'operations was', 'operations off', 'operations is', 'operation but', 'operations or', 'operations but', 'operations over', 'operational by', 'operations he',
'operations while', 'operations out', 'war operation', 'operation or', 'operation he', 'operational the', 'by operation', 'operational use', 'operational on', 'operations an', 'on operation',
'sting operation', 'operations when', 'under operation', 'operation when', 'operations per', 'or operation', 'operations unit', 'operation while', 'operation ivy', 'operation are', 'operations may',
'full operation', 'ii operation', 'operations she', 'his operation', 'operation s', 'operation just', 'operational at', 'operation an', 'one operation', 'see operation', 'operation over', 'was operation',
'over operation', 'operations task', 'operation may', 'operations one', 'operations will', 'operation if', 'operational as', 'operation will', 'cruz operation', 'operational for', 'operational risk',
'safe operation', 'out operation', 'operation one', 'no operation', 'same operation', 'operation el', 'operation she', 'operational unit', 'may operation', 'operations all', 'basic operation', 'up operation',
'operational plan', 'any operation', 'read operation', 'operation all', 'operations if', 'new operation', 'operation operation', 'operations no', 'operation so', 'operational base', 'operations air',
'operation i', 'operations plan', 'operations e', 'operations more', 'operational range', 'next operation', 'operations each', 'operational it', 'unary operation', 'led operation', 'operation ajax',
'px operation', 'operations both', 'nato operation'],
['requires two', 'require two'],
['contracting the', 'contracting and', 'contracting a'],
['syracuse ny', 'syracuse s'],
['limits', 'limit its', 'limits its'],
['noblewoman', 'noblewoman d', 'noblewoman b', 'a noblewoman'],
['a bs', 'b bs', 'f bs'], ['received special', 'receive special'],
['top s', 'top a', 'top u', 'top o'],
['southern egypt', 'northern egypt'],
['long distances', 'short distances'],
['the convention', 'a convention', 'by convention', 'and convention', 's convention', 'of convention', 'un convention', 'in convention', 'new convention', 'or convention', 'fan convention', 'to convention'],
['force its', 'forces its'],
['functions within', 'function within'],
['newspaper which', 'newspapers which'],
['a sample', 's sample', 'or sample'],
['seven members', 'eleven members', 'fifteen members', 'thirteen members'],
['mk v', 'mk a', 'mk x', 'mk t'],
['competitors', 'the competitors', 'of competitors', 'main competitors', 's competitors', 'to competitors', 'and competitors', 'by competitors', 'all competitors', 'as competitors', 'for competitors']]
In general the patterns I’ve seen, pretty much all of which are captured above
- A bi-gram with both plural and singular form
- a word with different articles
- related concepts (e.g., north, east, south, west)
- a bi-gram with a word and letter (e.g., top s, top o, etc..)
- Synonyms
An interesting caveat is that these groupings utility will be heavily use dependent. Like if cardinal directions matter in your problem, grouping north and south together is probably bad. I haven’t really explored this, just pointing it out.
Step 4. Creation of a Clustered and Control Features
These clustered labels were used for the vocab. As a control we compare the clustered vocab to a vocab that has the 1 Million most common n-grams. To adjust for the fact that the clustered vocab will have higher values by normalizing the output. “Unnormalized” embeddings would likely have been a confounding factor for certain types of models like Neural Networks.
Step 5. Train Downstream Models
Both these vocabs were used to train MLP classifiers over fetch_20newsgroups. Two models were trained, one using unigrams and another using both uni-grams and bi-grams. Macro-F1 score was computed for each run.
Step 6. Significance Testing
The F1 scores across both are compared across both models using permutation testing. 600 random states are used to evaluate performance. The Metric used to see if clustering is better than the control is the delta between the mean of a sample of both the clustered and control vocab.
Results & Analysis
Below is a plot of the distribution of F1 scores across both the reference and control.
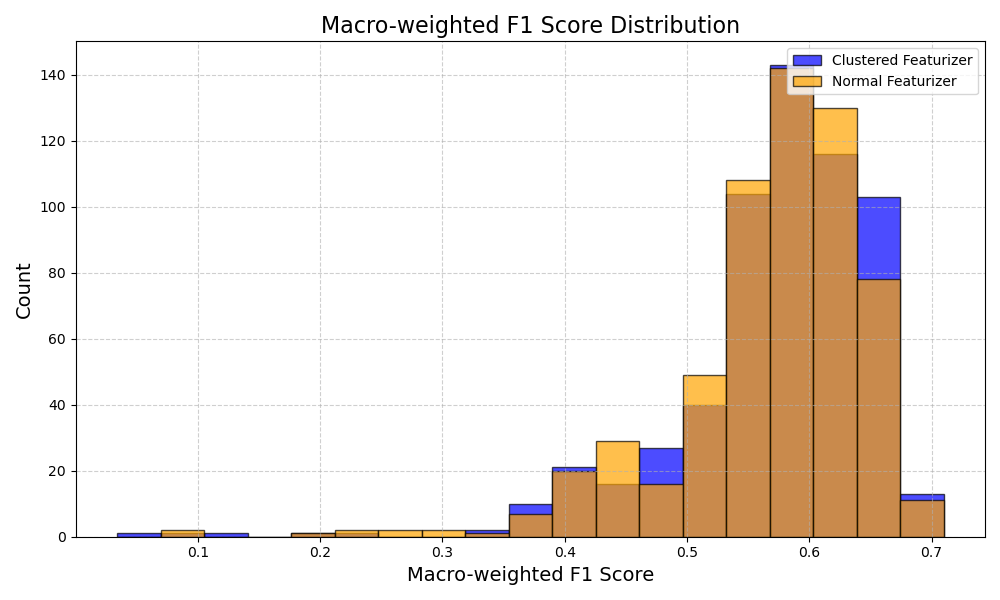
Results for the significance test are as follows:
| Max n-gram | Delta | Statistical Significance |
|---|---|---|
| 1 | 0.001 | 0.63 |
| 2 | 0.005 | 0.12 |
To put it bluntly, the results don’t show a statistically significant difference. Even if they did, the magnitude of the effect appears very small. I could likely increase the number of seeds and get statistical significance, but that wouldn’t change the fact that the difference in performance is tiny.
Takeaways, Next Steps, and Potential Improvements
I underestimated the complexity of comparing hashing groupings to a reference cluster. Even a simplified experiment failed to bear meaningful results. I think that is partially due to poor design choices.
To increase the validity of results and measure the effect,if any exists, synonymy I need to:
- To better understand how this approach fares across different domains and tasks I need to find and curate a larger bench test of classification tasks. I’m aware of large test datasets like BIG-bench, but want to avoid flawed datasets. This will require some time and research
- The embedding quality is OK, but likely could be better. I think using a pretrained word embedding or potentially even a contextual embedding (think BERT). Contextual embeddings would require changing the underlying approach. I’m not sure if it is necessary when using n-grams either
- Effect of different hyperparameter choices
- Try different settings for clustering, specifically the maximum distance. I want to see if that has an effect on the output
- Use of more unique n-grams
- Larger pretraining corpora/effect of pretraining corpora on performance
- Different pretraining domains or a better blend
- Larger number of n-grams or different combinations of n-grams (e.g., using 1-gram, 3-gram, 5-gram)
- Lack of polysemy. This could maybe solved for by using of multiple embeddings trained across different domains. Honestly not sure if this is worth tackling, but it dovetails nicely with the next point.
- Accounting for change in domain between the pretraining domain and downstream task. If some n-grams are uncommon in the target domain or were not present in the original dataset this could impact performance.