Dispelling NLP Myths: How Finetuning Compares to Prompting (Part 1)
With the rise of LLMs as an API
prompting is a tempting first option to tackle most problems, including classification.
Given how much model capabilities have improved over the last few years, it can seem obvious that prompting a larger model should beat finetuning a smaller model for a specific task.
In 2023 there was a graph that made the rounds on twitter that perpetuated this idea, see this post from Andrej Karpathy:
Here’s the graph in question:
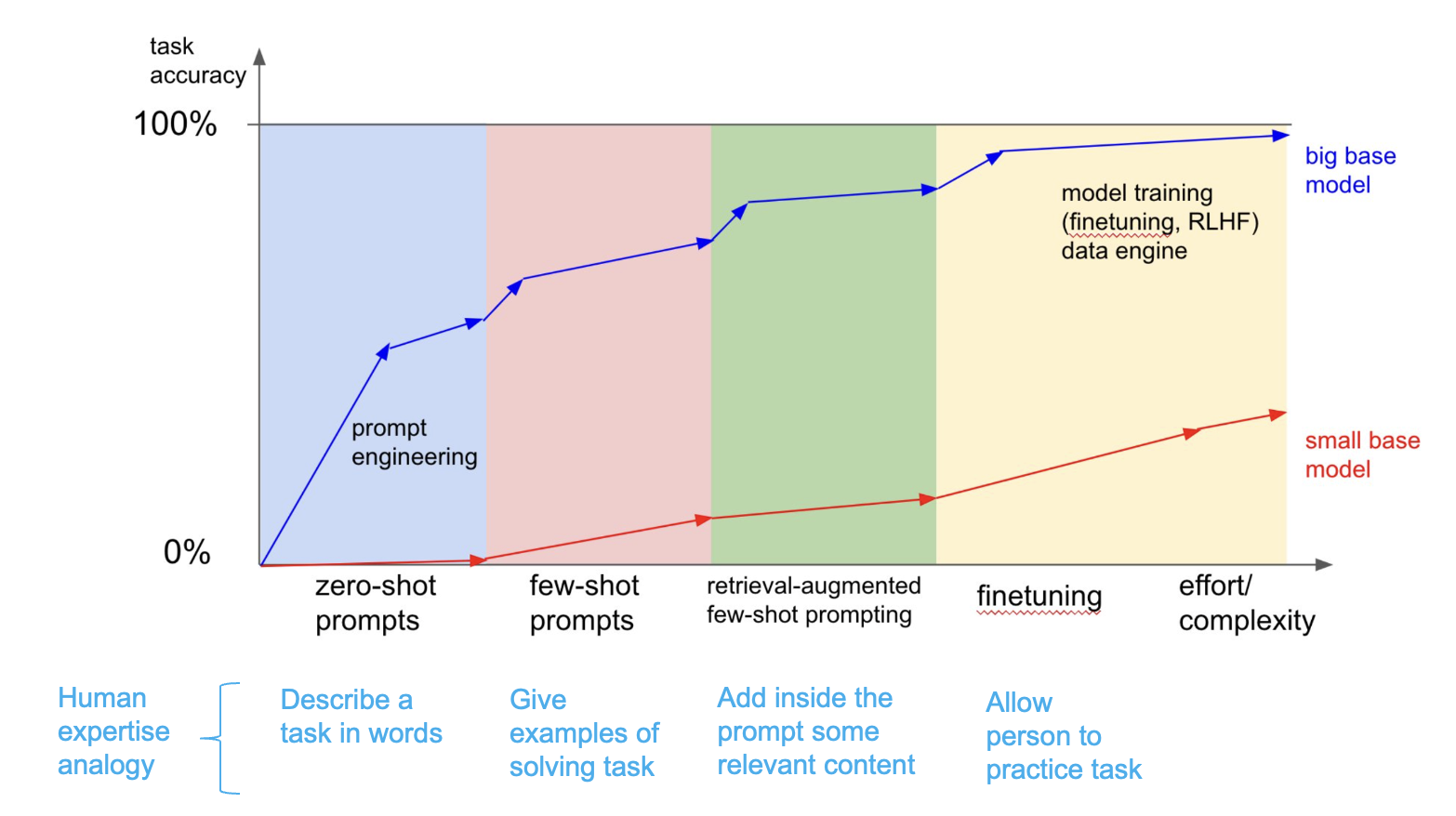
While the post indicates the graph shouldn’t be taken literally, I know a fair number of people who have accepted the notion that finetuned models are consistently outperformed by prompting as fact. I have gotten push back when proposing finetuning instead of stopping at prompting. The issue is we don’t always have enough data to be able to train and evaluate a model, so our ability to figure out if finetuning is better even just for a given task is limited. Due to this, myths about prompting vs finetuning get a lot of traction without much or any empirical verification. I’m curious how accurate (generally speaking) the implicit claims made by this infographic are specifically when it comes to model size and it’s correlation to performance. The following series of posts will present and discuss experiments comparing prompting to finetuning to help better understand when a given tool might make more sense. This first post is a pilot, but the result is already enough to make me skeptical of the default “just prompt a larger model” framing for classification.
What This Post Is Testing
The myth implies that prompting is by default better and finetuning models is not worth it. Classification gives us a straightforward setting to test the claim. The outputs are discrete, metrics are easier to interpret, and we can compare methods without relying on vibes. This first post is a pilot which compares prompted open-source decoders against finetuned Ettin encoders on GLUE CoLA using repeated runs.
The question here is not whether prompting is useful. It is whether prompting should remain the default when labeled classification data makes finetuning a realistic option:
Given a classification task with enough labeled data to finetune, should you prompt an instruction-tuned decoder or finetune a task-specific encoder?
Research Questions
This high-level question can be further broken down into sub-components (research questions) to understand what impacts finetuning, prompting performance, and how they compare. E.g., it is valuable to identify the variables that matter when prompting is used as a classifier: prompt choice, model family, model size, aggregation, and finetuned model size. To this end here are the top-level research questions this work aims to answer, with a detailed version that will be referenced below.
- What factors impact the performance of prompting?
- What factors effect the performance for finetuned models?
- How do prompt-based methods compare to finetuning on smaller (Encoder) models across different settings?
- Can we predict these trends before training a model? E.G., can we take a dataset and predict model performance without even training?
RQ Taxonomy (Aka the roadmap)
- What factors impact the performance of prompting?
- Given the brittleness and indeterminate nature of LLMs, how variable are outputs?
- How does temperature effect performance?
- How do different prompts effect performance?
- How does performance change for a specific model & prompt combo across runs?
- How does reasoning effect performance? Specifically the amount and placement?
- Do additional systems around a prompt improve performance?
- Effects of aggregation methods on performances
- Effect of k-shot as k -> inf
- Effect of RAG on classification
- Are there trends in performance across metadata?
- Model families
- Model size
- density
- Reasoning
- Effect of data on performance
- Was data previously seen by model
- Domain variability
- Given the brittleness and indeterminate nature of LLMs, how variable are outputs?
- What factors effect the performance for finetuned models?
- Effect of amount of data on performance?
- Effects of model size on finetuning?
- Effect of model family (BERT, ModernBERT, Ettin)
- Effect of encoder vs decoder
- How do prompt-based methods compare to finetuning on smaller (Encoder) models across different settings?
- Data efficiency (k-shot prompting vs finetune vs k examples)
- How do prompting and finetuning compare
- Effects and trends across different datasets and tasks
- Can we predict these trends before training a model? E.G., can we take a dataset and predict model performance without even training?
Questions 1 and 2 may seem like asides, but they aim to further explore what variables play a role in the success or failure of prompting and finetuning respctively. E.G., how large of a role does model size play? Understanding the knobs at play and their effects is meant to help understand trade offs between the two techniques in more depth and ablate/account for the variables in this experiment.
If you haven’t already I recommend looking at the detailed RQ taxonomy as it will be referenced throughout the rest of the post and subsequent posts. It will serve as a roadmap.
Caveats
Before going further with this post, note that is a pilot study and as such has limitations. Below are a few risks and the reasons:
- limited size of models: prompting is currently limited to open-weight models I could run locally, <=32B range
- artifacts from inference engine: models were run exclusively on llama.cpp using 8 bit or less models
- limited scope of results: only GLUE cola was used, who knows what performance is for other datasets
- data contamination: GLUE is a widespread benchmark
- limited finetuning models: only Ettin encoders are used, with fixed hyperparameters
- evaluation metrics: I plan on using F1 across the board to have a consistent metric even if that wasn’t a metric originally used for the dataset
Ok with that out of the way, on with the show.
Methodology
This first post is a pilot and will be limited in scope. Specifically these RQs will be tackled:
- 1.1.2 & 1.1.3: How do different prompts affect performance?
- 1.2.1: Does aggregation improve prompting?
- 1.3.1: How does model family affect prompting performance?
- 1.3.2: How does model size affect prompting performance?
- 1.3.3: How do MoEs compare to dense models?
- 2.2: How does model size affect finetuning?
- 3.2: How do finetuning and prompting compare?
The general idea is simple, a bunch of encoders are trained and compared to (larger) open source decoders across a set of prompts over a validation set. The experiments are divided into “runs” to account for variability across different settings whether that’s randomness in prompt performance, decoding, or finetuning for the encoders. This makes for a large number of experiments. These “runs” are different across the finetune and prompt setting.
The finetuned models are trained 10 times with different seeds over the full data. Each model with a different seed is a “run”. Each run has its macro F1, precision, and recall calculated.
Similarly the prompt based runs are run 10 times for each model and each prompt. The prompt-based runs used each model’s documented default or recommended temperature when one was available.
Outputs are in JSON format, with rationale first, class after. The raw outputs are stored in a database and the metrics (macro F1, precision, and recall)
are calculated independently for each run. For aggregate runs the same process is repeated for a given combination of
\(\binom{n}{k}\) original runs. For each input, predictions are voted across the \(n\) runs. Ties are broken with Python’s sorted function.
The research questions are all subsets of the larger experiment.
Dataset(s)
The results in this post are limited to one dataset GLUE Cola. This dataset is a simple binary text classification dataset, GLUE being a staple of the BERTology era. It’s not too large either (8k training, 1.7K val), making it a good place to start.
One challenge was crafting prompts for these experiments. I debated between a couple of options, namely
- hand-crafting my own prompts
- LLM written prompts
- using an existing prompt dataset
Given the time constraints and bias involved with 1 prompt writer, 1 was off the table. 2 introduces variables with respect to prompt, are the prompts suited for their purpose, can prompts introduce leakage, etc.. Option 3 made the most sense in this context. The primary con is that the number of prompts available is limited, but that’s OK. Prompt source has about 200 tasks with prompts and I’ve identified about 30 classification tasks that are well suited for my purposes. There are likely more, but for now these 30 fit my criteria of size, availability of a validation split, and adequate number of prompts.
Models
Finetuning Models
Finetuned models are varying sizes of Ettin models, specifically the encoders. This post is limited to encoders because they appear to be better suited for classification than decoder models. The reasons for choosing the Ettin suite of models were
- modern architecture, not unlike the prompting models
- 1T+ pretraining data
- choice between encoders and decoders (in the future)
- variety of sizes, especially 1B model which is a harder size to find for encoders
For now the finetuning hyper-parameters are fixed (see below). Eventually the goal is to optimize HPs across all the experiments using k-fold validation (which is realistic in industry settings IMO), but for simplicity’s sake I’ve set that aside for now.
Finetuning Hyperparameters
k_fold = -1 # set to a higher number to activate
current_fold = 0
num_epochs = 5
learning_rate = 2e-5
batch_size = 16
weight_decay = 0.01
Prompting Models
For prompting, the setup was limited to <= 32B open source models for computational reasons, i.e., Ryzen AI Max 395+ from my homelab was used. Models were served using llama.cpp using 8bit ggufs unless otherwise specified. This decision was made as a way of balancing performance and compute costs. Below is a comprehensive list of models used and decoding settings used. The models are divided into “tracks”, with each track trying to measure a different relationship across models (e.g., size, generation, model families, density). These tracks are used to facilitate comparison when it comes to the RQs. They do not effect how or which models were run.
Experiment Tracks
HF_MODELS = [
# Track 1: cross-family baseline
"meta-llama/Meta-Llama-3-8B-Instruct",
"microsoft/Phi-3-small-8k-instruct",
"google/gemma-2-9b-it",
"Qwen/Qwen2.5-7B-Instruct",
# Track 2: Qwen size sweep
"Qwen/Qwen2.5-1.5B-Instruct",
"Qwen/Qwen2.5-7B-Instruct",
"Qwen/Qwen2.5-14B-Instruct",
"Qwen/Qwen2.5-32B-Instruct",
# Track 3: Qwen generation sweep
"Qwen/Qwen-7B-Chat",
"Qwen/Qwen1.5-7B-Chat",
"Qwen/Qwen2-7B-Instruct",
"Qwen/Qwen2.5-7B-Instruct",
"Qwen/Qwen3-8B",
"Qwen/Qwen3.5-9B",
# Track 4: density
"Qwen/Qwen3-32B",
"Qwen/Qwen3-30B-A3B",
"google/gemma-4-31B-it",
"google/gemma-4-26B-A4B-it",
]
Decoding Hyperparameters for Prompting
| Model | Temp | Basis | Reference |
|---|---|---|---|
meta-llama/Meta-Llama-3-8B-Instruct |
0.6 | Official HF example / generation config usage | (Hugging Face) |
microsoft/Phi-3-small-8k-instruct |
0.0 | Official HF example sets temperature=0.0, do_sample=False |
(Hugging Face) |
google/gemma-2-9b-it |
0.3 | Google-org HF discussion says the recommended lower temp is 0.3 |
(Hugging Face) |
Qwen/Qwen2.5-7B-Instruct |
0.7 | Official HF generation_config.json |
(Hugging Face) |
Qwen/Qwen2.5-1.5B-Instruct |
0.7 | Official HF generation_config.json |
(Hugging Face) |
Qwen/Qwen2.5-14B-Instruct |
0.7 | Official HF generation_config.json |
(Hugging Face) |
Qwen/Qwen2.5-32B-Instruct |
0.7 | Official HF generation_config.json |
(Hugging Face) |
Qwen/Qwen-7B-Chat |
0.7 | Proxy: official config has no temp; pinned to later Qwen chat/instruct family default and Qwen-team guidance | (Hugging Face) |
Qwen/Qwen1.5-7B-Chat |
0.7 | Official HF generation_config.json / official docs example |
(Hugging Face) |
Qwen/Qwen2-7B-Instruct |
0.7 | Official HF generation_config.json |
(Hugging Face) |
Qwen/Qwen3-8B |
0.6 | Official HF generation_config.json; model card says thinking mode uses 0.6 |
(Hugging Face) |
Qwen/Qwen3.5-9B |
1.0 | Official model card recommends 1.0 for thinking mode general tasks; model thinks by default |
(Hugging Face) |
Qwen/Qwen3-14B |
0.6 | Official HF generation_config.json; model card says thinking mode uses 0.6 |
(Hugging Face) |
Qwen/Qwen3-32B |
0.6 | Official HF generation_config.json; model card says thinking mode uses 0.6 |
(Hugging Face) |
Qwen/Qwen3-30B-A3B |
0.6 | Official HF generation_config.json; same Qwen3 thinking-mode default |
(Hugging Face) |
google/gemma-4-31B-it |
1.0 | Official Gemma 4 model card says use temperature=1.0 across use cases |
(Hugging Face) |
google/gemma-4-26B-A4B-it |
1.0 | Official Gemma 4 family card says use temperature=1.0 across use cases |
(Google AI for Developers) |
Evaluation
For each “run” the macro precision, recall, F1 over validation are reported. Rather than present a single metric, all 3 are presented. Accuracy is not necessarily a telling metric so I’ve excluded it. I know GLUE Cola is typically presented using Matthew’s correlation. In my context I’m more interested in having a uniform metric across multiple datasets. While it does make my results harder to compare to past literature, I don’t think F1 is inherently invalid or not applicable to this (or most) datasets.
Results
The main research question is 3.2: how do finetuning and prompting compare? The other research questions in 1.x and 2.x help get to the heart of that by accounting for confounders such as prompt sensitivity, run-to-run variance, model family, model size, aggregation, and finetuned encoder size. Otherwise, the comparison is too easy to dismiss as one bad prompt, one weak model family, or one unlucky run. The following sections are evidence that the final comparison is part of a trend rather than a blip.
1.1.2 & 1.1.3 How do different prompts affect performance?
This might not be shocking, but prompts matter a lot. These two RQs explore the interplay between models and prompts and their effect on performance.
This first graph groups together model performance by prompt.
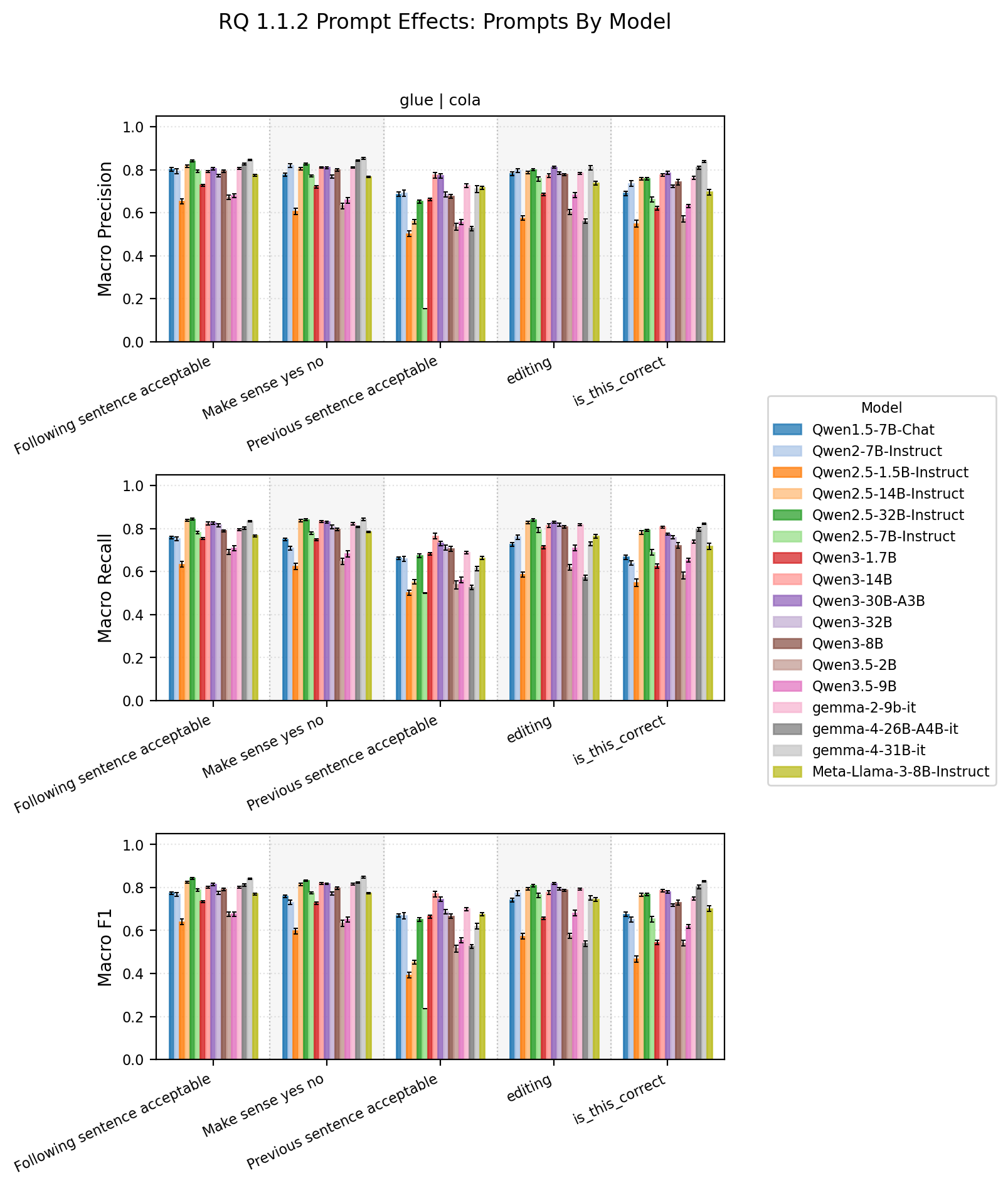
Prompt by model summary statistics
| dataset_name | subset_name | prompt_name | model_name | macro_precision_mean_std | macro_precision_median | macro_recall_mean_std | macro_recall_median | macro_f1_mean_std | macro_f1_median |
|---|---|---|---|---|---|---|---|---|---|
| glue | cola | Following sentence acceptable | Qwen/Qwen1.5-7B-Chat | 0.8017 +- 0.0082 | 0.8019 | 0.7579 +- 0.0058 | 0.7594 | 0.7734 +- 0.0064 | 0.7753 |
| glue | cola | Following sentence acceptable | Qwen/Qwen2-7B-Instruct | 0.7938 +- 0.0117 | 0.7974 | 0.7537 +- 0.0086 | 0.7552 | 0.7681 +- 0.0095 | 0.7709 |
| glue | cola | Following sentence acceptable | Qwen/Qwen2.5-1.5B-Instruct | 0.6525 +- 0.0123 | 0.6573 | 0.6342 +- 0.0126 | 0.6347 | 0.6399 +- 0.0128 | 0.6407 |
| glue | cola | Following sentence acceptable | Qwen/Qwen2.5-14B-Instruct | 0.8165 +- 0.0048 | 0.8168 | 0.8375 +- 0.0047 | 0.8374 | 0.8250 +- 0.0047 | 0.8252 |
| glue | cola | Following sentence acceptable | Qwen/Qwen2.5-32B-Instruct | 0.8409 +- 0.0042 | 0.8403 | 0.8434 +- 0.0040 | 0.8427 | 0.8421 +- 0.0039 | 0.8418 |
| glue | cola | Following sentence acceptable | Qwen/Qwen2.5-7B-Instruct | 0.7925 +- 0.0067 | 0.7930 | 0.7821 +- 0.0050 | 0.7814 | 0.7868 +- 0.0057 | 0.7865 |
| glue | cola | Following sentence acceptable | Qwen/Qwen3-1.7B | 0.7279 +- 0.0043 | 0.7288 | 0.7535 +- 0.0052 | 0.7544 | 0.7349 +- 0.0045 | 0.7359 |
| glue | cola | Following sentence acceptable | Qwen/Qwen3-14B | 0.7910 +- 0.0046 | 0.7902 | 0.8238 +- 0.0068 | 0.8227 | 0.8009 +- 0.0048 | 0.8001 |
| glue | cola | Following sentence acceptable | Qwen/Qwen3-30B-A3B | 0.8047 +- 0.0057 | 0.8043 | 0.8260 +- 0.0065 | 0.8264 | 0.8132 +- 0.0059 | 0.8131 |
| glue | cola | Following sentence acceptable | Qwen/Qwen3-32B | 0.7719 +- 0.0063 | 0.7710 | 0.8160 +- 0.0070 | 0.8150 | 0.7741 +- 0.0074 | 0.7728 |
| glue | cola | Following sentence acceptable | Qwen/Qwen3-8B | 0.7937 +- 0.0063 | 0.7941 | 0.7892 +- 0.0055 | 0.7886 | 0.7913 +- 0.0059 | 0.7913 |
| glue | cola | Following sentence acceptable | Qwen/Qwen3.5-2B | 0.6709 +- 0.0104 | 0.6703 | 0.6901 +- 0.0115 | 0.6893 | 0.6752 +- 0.0109 | 0.6749 |
| glue | cola | Following sentence acceptable | Qwen/Qwen3.5-9B | 0.6796 +- 0.0093 | 0.6804 | 0.7091 +- 0.0109 | 0.7105 | 0.6758 +- 0.0096 | 0.6753 |
| glue | cola | Following sentence acceptable | google/gemma-2-9b-it | 0.8064 +- 0.0035 | 0.8059 | 0.7951 +- 0.0042 | 0.7957 | 0.8003 +- 0.0038 | 0.8003 |
| glue | cola | Following sentence acceptable | google/gemma-4-26B-A4B-it | 0.8254 +- 0.0043 | 0.8255 | 0.8014 +- 0.0058 | 0.8021 | 0.8115 +- 0.0052 | 0.8120 |
| glue | cola | Following sentence acceptable | google/gemma-4-31B-it | 0.8459 +- 0.0033 | 0.8460 | 0.8350 +- 0.0029 | 0.8354 | 0.8401 +- 0.0030 | 0.8404 |
| glue | cola | Following sentence acceptable | meta-llama/Meta-Llama-3-8B-Instruct | 0.7742 +- 0.0049 | 0.7731 | 0.7657 +- 0.0042 | 0.7647 | 0.7696 +- 0.0045 | 0.7686 |
| glue | cola | Make sense yes no | Qwen/Qwen1.5-7B-Chat | 0.7765 +- 0.0066 | 0.7758 | 0.7490 +- 0.0055 | 0.7469 | 0.7597 +- 0.0059 | 0.7575 |
| glue | cola | Make sense yes no | Qwen/Qwen2-7B-Instruct | 0.8191 +- 0.0081 | 0.8198 | 0.7079 +- 0.0085 | 0.7068 | 0.7308 +- 0.0094 | 0.7299 |
| glue | cola | Make sense yes no | Qwen/Qwen2.5-1.5B-Instruct | 0.6061 +- 0.0132 | 0.6103 | 0.6238 +- 0.0153 | 0.6288 | 0.5970 +- 0.0142 | 0.6010 |
| glue | cola | Make sense yes no | Qwen/Qwen2.5-14B-Instruct | 0.8046 +- 0.0053 | 0.8040 | 0.8382 +- 0.0057 | 0.8366 | 0.8151 +- 0.0055 | 0.8146 |
| glue | cola | Make sense yes no | Qwen/Qwen2.5-32B-Instruct | 0.8263 +- 0.0032 | 0.8263 | 0.8413 +- 0.0040 | 0.8401 | 0.8328 +- 0.0032 | 0.8326 |
| glue | cola | Make sense yes no | Qwen/Qwen2.5-7B-Instruct | 0.7712 +- 0.0047 | 0.7706 | 0.7789 +- 0.0061 | 0.7785 | 0.7747 +- 0.0053 | 0.7745 |
| glue | cola | Make sense yes no | Qwen/Qwen3-1.7B | 0.7203 +- 0.0051 | 0.7198 | 0.7487 +- 0.0051 | 0.7490 | 0.7262 +- 0.0055 | 0.7257 |
| glue | cola | Make sense yes no | Qwen/Qwen3-14B | 0.8101 +- 0.0041 | 0.8090 | 0.8334 +- 0.0051 | 0.8317 | 0.8192 +- 0.0043 | 0.8179 |
| glue | cola | Make sense yes no | Qwen/Qwen3-30B-A3B | 0.8091 +- 0.0037 | 0.8089 | 0.8298 +- 0.0036 | 0.8293 | 0.8175 +- 0.0036 | 0.8173 |
| glue | cola | Make sense yes no | Qwen/Qwen3-32B | 0.7673 +- 0.0074 | 0.7669 | 0.8084 +- 0.0079 | 0.8075 | 0.7722 +- 0.0084 | 0.7728 |
| glue | cola | Make sense yes no | Qwen/Qwen3-8B | 0.7980 +- 0.0060 | 0.7983 | 0.7957 +- 0.0060 | 0.7957 | 0.7968 +- 0.0058 | 0.7971 |
| glue | cola | Make sense yes no | Qwen/Qwen3.5-2B | 0.6313 +- 0.0135 | 0.6315 | 0.6475 +- 0.0148 | 0.6486 | 0.6330 +- 0.0145 | 0.6331 |
| glue | cola | Make sense yes no | Qwen/Qwen3.5-9B | 0.6574 +- 0.0125 | 0.6594 | 0.6838 +- 0.0147 | 0.6864 | 0.6505 +- 0.0128 | 0.6522 |
| glue | cola | Make sense yes no | google/gemma-2-9b-it | 0.8101 +- 0.0036 | 0.8095 | 0.8226 +- 0.0045 | 0.8232 | 0.8157 +- 0.0039 | 0.8156 |
| glue | cola | Make sense yes no | google/gemma-4-26B-A4B-it | 0.8430 +- 0.0035 | 0.8434 | 0.8080 +- 0.0034 | 0.8080 | 0.8220 +- 0.0032 | 0.8222 |
| glue | cola | Make sense yes no | google/gemma-4-31B-it | 0.8527 +- 0.0050 | 0.8539 | 0.8437 +- 0.0055 | 0.8437 | 0.8479 +- 0.0052 | 0.8485 |
| glue | cola | Make sense yes no | meta-llama/Meta-Llama-3-8B-Instruct | 0.7672 +- 0.0034 | 0.7659 | 0.7847 +- 0.0035 | 0.7843 | 0.7742 +- 0.0034 | 0.7731 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen1.5-7B-Chat | 0.6862 +- 0.0095 | 0.6813 | 0.6615 +- 0.0062 | 0.6602 | 0.6696 +- 0.0069 | 0.6674 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen2-7B-Instruct | 0.6911 +- 0.0151 | 0.6978 | 0.6591 +- 0.0123 | 0.6628 | 0.6685 +- 0.0133 | 0.6730 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen2.5-1.5B-Instruct | 0.5025 +- 0.0134 | 0.5013 | 0.5021 +- 0.0111 | 0.5010 | 0.3925 +- 0.0128 | 0.3898 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen2.5-14B-Instruct | 0.5580 +- 0.0107 | 0.5584 | 0.5523 +- 0.0096 | 0.5527 | 0.4517 +- 0.0094 | 0.4501 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen2.5-32B-Instruct | 0.6513 +- 0.0083 | 0.6483 | 0.6736 +- 0.0091 | 0.6705 | 0.6512 +- 0.0094 | 0.6489 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen2.5-7B-Instruct | 0.1543 +- 0.0001 | 0.1544 | 0.4998 +- 0.0005 | 0.5000 | 0.2358 +- 0.0002 | 0.2359 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen3-1.7B | 0.6619 +- 0.0065 | 0.6623 | 0.6825 +- 0.0069 | 0.6830 | 0.6651 +- 0.0071 | 0.6653 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen3-14B | 0.7745 +- 0.0123 | 0.7719 | 0.7650 +- 0.0126 | 0.7671 | 0.7693 +- 0.0123 | 0.7688 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen3-30B-A3B | 0.7714 +- 0.0108 | 0.7716 | 0.7309 +- 0.0097 | 0.7325 | 0.7448 +- 0.0100 | 0.7462 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen3-32B | 0.6849 +- 0.0103 | 0.6853 | 0.7117 +- 0.0118 | 0.7120 | 0.6871 +- 0.0108 | 0.6877 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen3-8B | 0.6754 +- 0.0095 | 0.6738 | 0.7053 +- 0.0111 | 0.7033 | 0.6664 +- 0.0107 | 0.6647 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen3.5-2B | 0.5334 +- 0.0160 | 0.5386 | 0.5391 +- 0.0187 | 0.5452 | 0.5158 +- 0.0160 | 0.5212 |
| glue | cola | Previous sentence acceptable | Qwen/Qwen3.5-9B | 0.5553 +- 0.0117 | 0.5569 | 0.5612 +- 0.0133 | 0.5622 | 0.5547 +- 0.0119 | 0.5570 |
| glue | cola | Previous sentence acceptable | google/gemma-2-9b-it | 0.7257 +- 0.0098 | 0.7228 | 0.6880 +- 0.0061 | 0.6879 | 0.6997 +- 0.0070 | 0.6994 |
| glue | cola | Previous sentence acceptable | google/gemma-4-26B-A4B-it | 0.5259 +- 0.0100 | 0.5286 | 0.5255 +- 0.0099 | 0.5283 | 0.5256 +- 0.0100 | 0.5284 |
| glue | cola | Previous sentence acceptable | google/gemma-4-31B-it | 0.7097 +- 0.0153 | 0.7082 | 0.6144 +- 0.0102 | 0.6137 | 0.6194 +- 0.0128 | 0.6187 |
| glue | cola | Previous sentence acceptable | meta-llama/Meta-Llama-3-8B-Instruct | 0.7157 +- 0.0084 | 0.7130 | 0.6628 +- 0.0066 | 0.6602 | 0.6752 +- 0.0073 | 0.6729 |
| glue | cola | editing | Qwen/Qwen1.5-7B-Chat | 0.7804 +- 0.0081 | 0.7812 | 0.7256 +- 0.0084 | 0.7276 | 0.7424 +- 0.0086 | 0.7451 |
| glue | cola | editing | Qwen/Qwen2-7B-Instruct | 0.7950 +- 0.0088 | 0.7944 | 0.7602 +- 0.0111 | 0.7601 | 0.7733 +- 0.0104 | 0.7731 |
| glue | cola | editing | Qwen/Qwen2.5-1.5B-Instruct | 0.5754 +- 0.0111 | 0.5734 | 0.5856 +- 0.0124 | 0.5829 | 0.5730 +- 0.0124 | 0.5707 |
| glue | cola | editing | Qwen/Qwen2.5-14B-Instruct | 0.7868 +- 0.0059 | 0.7874 | 0.8285 +- 0.0060 | 0.8293 | 0.7943 +- 0.0067 | 0.7948 |
| glue | cola | editing | Qwen/Qwen2.5-32B-Instruct | 0.7993 +- 0.0047 | 0.7996 | 0.8399 +- 0.0058 | 0.8408 | 0.8087 +- 0.0049 | 0.8089 |
| glue | cola | editing | Qwen/Qwen2.5-7B-Instruct | 0.7569 +- 0.0099 | 0.7572 | 0.7932 +- 0.0110 | 0.7939 | 0.7635 +- 0.0107 | 0.7641 |
| glue | cola | editing | Qwen/Qwen3-1.7B | 0.6837 +- 0.0060 | 0.6819 | 0.7133 +- 0.0067 | 0.7110 | 0.6577 +- 0.0058 | 0.6547 |
| glue | cola | editing | Qwen/Qwen3-14B | 0.7722 +- 0.0075 | 0.7733 | 0.8144 +- 0.0080 | 0.8168 | 0.7768 +- 0.0086 | 0.7769 |
| glue | cola | editing | Qwen/Qwen3-30B-A3B | 0.8108 +- 0.0048 | 0.8115 | 0.8291 +- 0.0049 | 0.8280 | 0.8184 +- 0.0047 | 0.8188 |
| glue | cola | editing | Qwen/Qwen3-32B | 0.7839 +- 0.0056 | 0.7845 | 0.8180 +- 0.0062 | 0.8195 | 0.7934 +- 0.0058 | 0.7939 |
| glue | cola | editing | Qwen/Qwen3-8B | 0.7773 +- 0.0040 | 0.7789 | 0.8078 +- 0.0049 | 0.8087 | 0.7866 +- 0.0042 | 0.7882 |
| glue | cola | editing | Qwen/Qwen3.5-2B | 0.6031 +- 0.0120 | 0.6004 | 0.6196 +- 0.0137 | 0.6165 | 0.5746 +- 0.0111 | 0.5743 |
| glue | cola | editing | Qwen/Qwen3.5-9B | 0.6813 +- 0.0118 | 0.6788 | 0.7100 +- 0.0135 | 0.7068 | 0.6802 +- 0.0132 | 0.6786 |
| glue | cola | editing | google/gemma-2-9b-it | 0.7831 +- 0.0039 | 0.7825 | 0.8178 +- 0.0044 | 0.8172 | 0.7924 +- 0.0041 | 0.7918 |
| glue | cola | editing | google/gemma-4-26B-A4B-it | 0.5607 +- 0.0098 | 0.5616 | 0.5709 +- 0.0116 | 0.5720 | 0.5392 +- 0.0124 | 0.5385 |
| glue | cola | editing | google/gemma-4-31B-it | 0.8101 +- 0.0101 | 0.8105 | 0.7300 +- 0.0093 | 0.7334 | 0.7515 +- 0.0099 | 0.7546 |
| glue | cola | editing | meta-llama/Meta-Llama-3-8B-Instruct | 0.7372 +- 0.0081 | 0.7373 | 0.7649 +- 0.0084 | 0.7665 | 0.7445 +- 0.0085 | 0.7443 |
| glue | cola | is_this_correct | Qwen/Qwen1.5-7B-Chat | 0.6892 +- 0.0098 | 0.6909 | 0.6672 +- 0.0107 | 0.6704 | 0.6748 +- 0.0107 | 0.6778 |
| glue | cola | is_this_correct | Qwen/Qwen2-7B-Instruct | 0.7359 +- 0.0122 | 0.7382 | 0.6393 +- 0.0096 | 0.6381 | 0.6503 +- 0.0116 | 0.6490 |
| glue | cola | is_this_correct | Qwen/Qwen2.5-1.5B-Instruct | 0.5487 +- 0.0168 | 0.5516 | 0.5484 +- 0.0165 | 0.5508 | 0.4670 +- 0.0152 | 0.4702 |
| glue | cola | is_this_correct | Qwen/Qwen2.5-14B-Instruct | 0.7576 +- 0.0068 | 0.7598 | 0.7812 +- 0.0078 | 0.7836 | 0.7657 +- 0.0071 | 0.7680 |
| glue | cola | is_this_correct | Qwen/Qwen2.5-32B-Instruct | 0.7587 +- 0.0053 | 0.7599 | 0.7919 +- 0.0058 | 0.7940 | 0.7666 +- 0.0057 | 0.7676 |
| glue | cola | is_this_correct | Qwen/Qwen2.5-7B-Instruct | 0.6616 +- 0.0117 | 0.6621 | 0.6890 +- 0.0137 | 0.6898 | 0.6529 +- 0.0125 | 0.6527 |
| glue | cola | is_this_correct | Qwen/Qwen3-1.7B | 0.6200 +- 0.0090 | 0.6219 | 0.6254 +- 0.0096 | 0.6261 | 0.5440 +- 0.0094 | 0.5426 |
| glue | cola | is_this_correct | Qwen/Qwen3-14B | 0.7753 +- 0.0054 | 0.7763 | 0.8078 +- 0.0044 | 0.8089 | 0.7843 +- 0.0058 | 0.7854 |
| glue | cola | is_this_correct | Qwen/Qwen3-30B-A3B | 0.7852 +- 0.0068 | 0.7854 | 0.7735 +- 0.0047 | 0.7733 | 0.7788 +- 0.0053 | 0.7785 |
| glue | cola | is_this_correct | Qwen/Qwen3-32B | 0.7221 +- 0.0055 | 0.7228 | 0.7597 +- 0.0064 | 0.7605 | 0.7169 +- 0.0059 | 0.7178 |
| glue | cola | is_this_correct | Qwen/Qwen3-8B | 0.7421 +- 0.0122 | 0.7418 | 0.7217 +- 0.0120 | 0.7198 | 0.7298 +- 0.0119 | 0.7278 |
| glue | cola | is_this_correct | Qwen/Qwen3.5-2B | 0.5709 +- 0.0133 | 0.5701 | 0.5820 +- 0.0153 | 0.5805 | 0.5406 +- 0.0132 | 0.5379 |
| glue | cola | is_this_correct | Qwen/Qwen3.5-9B | 0.6310 +- 0.0077 | 0.6314 | 0.6534 +- 0.0091 | 0.6539 | 0.6182 +- 0.0080 | 0.6173 |
| glue | cola | is_this_correct | google/gemma-2-9b-it | 0.7615 +- 0.0080 | 0.7621 | 0.7401 +- 0.0066 | 0.7398 | 0.7487 +- 0.0070 | 0.7483 |
| glue | cola | is_this_correct | google/gemma-4-26B-A4B-it | 0.8099 +- 0.0075 | 0.8096 | 0.7974 +- 0.0089 | 0.7966 | 0.8030 +- 0.0081 | 0.8026 |
| glue | cola | is_this_correct | google/gemma-4-31B-it | 0.8371 +- 0.0045 | 0.8362 | 0.8234 +- 0.0033 | 0.8234 | 0.8296 +- 0.0036 | 0.8292 |
| glue | cola | is_this_correct | meta-llama/Meta-Llama-3-8B-Instruct | 0.6956 +- 0.0124 | 0.6969 | 0.7164 +- 0.0143 | 0.7173 | 0.7012 +- 0.0129 | 0.7027 |
When aggregating together performance per model, we see a trend. Some prompts,
namely “Previous sentence acceptable” are on average poorer and have higher variability across models.
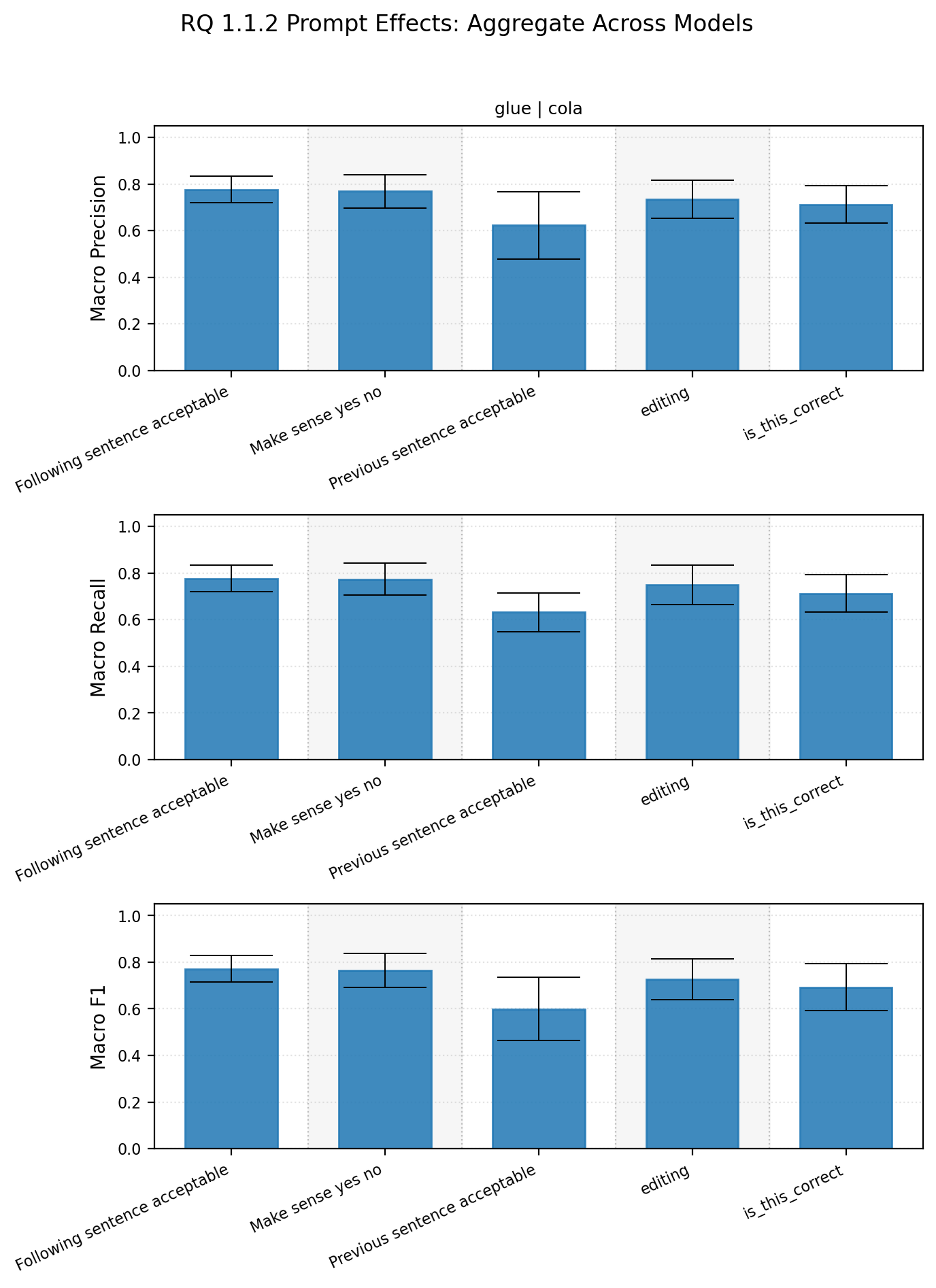
Prompt-level aggregate
| dataset_name | subset_name | prompt_name | macro_precision_mean_std | macro_precision_median | macro_recall_mean_std | macro_recall_median | macro_f1_mean_std | macro_f1_median |
|---|---|---|---|---|---|---|---|---|
| glue | cola | Following sentence acceptable | 0.7759 +- 0.0573 | 0.7941 | 0.7773 +- 0.0563 | 0.7886 | 0.7719 +- 0.0576 | 0.7859 |
| glue | cola | Make sense yes no | 0.7688 +- 0.0716 | 0.7961 | 0.7732 +- 0.0683 | 0.7938 | 0.7638 +- 0.0726 | 0.7792 |
| glue | cola | Previous sentence acceptable | 0.6222 +- 0.1442 | 0.6708 | 0.6315 +- 0.0832 | 0.6605 | 0.5995 +- 0.1350 | 0.6578 |
| glue | cola | editing | 0.7351 +- 0.0814 | 0.7773 | 0.7488 +- 0.0845 | 0.7675 | 0.7277 +- 0.0875 | 0.7612 |
| glue | cola | is_this_correct | 0.7119 +- 0.0804 | 0.7311 | 0.7128 +- 0.0810 | 0.7240 | 0.6925 +- 0.1002 | 0.7178 |
Looking at the corollary, we see some models are more robust to model variations as well.
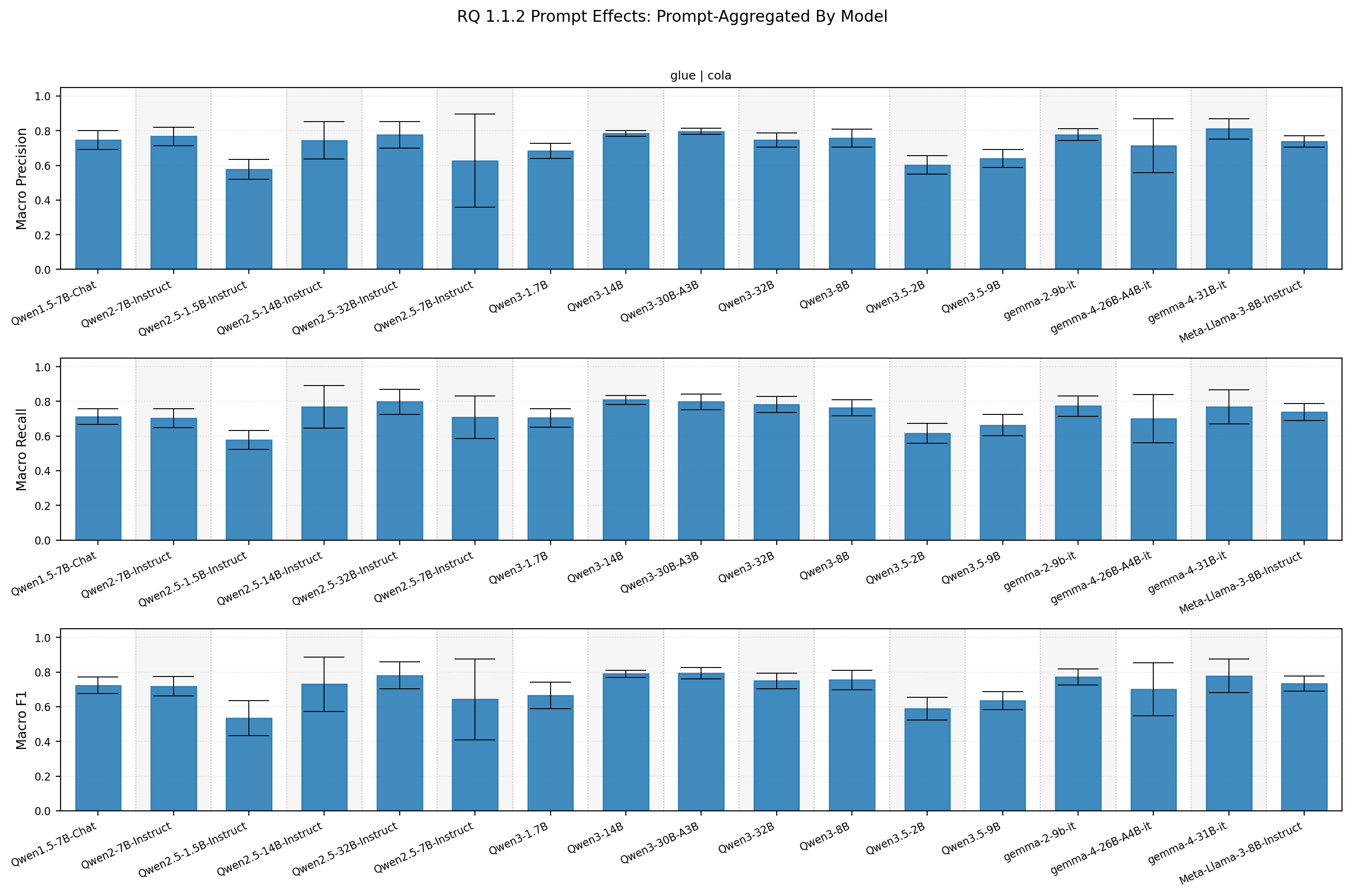
Model-level aggregation
| dataset_name | subset_name | model_name | macro_precision_mean_std | macro_precision_median | macro_recall_mean_std | macro_recall_median | macro_f1_mean_std | macro_f1_median |
|---|---|---|---|---|---|---|---|---|
| glue | cola | Qwen/Qwen1.5-7B-Chat | 0.7468 +- 0.0548 | 0.7765 | 0.7122 +- 0.0453 | 0.7256 | 0.7240 +- 0.0486 | 0.7424 |
| glue | cola | Qwen/Qwen2-7B-Instruct | 0.7670 +- 0.0523 | 0.7938 | 0.7040 +- 0.0544 | 0.7079 | 0.7182 +- 0.0565 | 0.7308 |
| glue | cola | Qwen/Qwen2.5-1.5B-Instruct | 0.5770 +- 0.0568 | 0.5754 | 0.5788 +- 0.0546 | 0.5856 | 0.5339 +- 0.1015 | 0.5730 |
| glue | cola | Qwen/Qwen2.5-14B-Instruct | 0.7447 +- 0.1067 | 0.7868 | 0.7675 +- 0.1226 | 0.8285 | 0.7303 +- 0.1574 | 0.7943 |
| glue | cola | Qwen/Qwen2.5-32B-Instruct | 0.7753 +- 0.0760 | 0.7993 | 0.7980 +- 0.0728 | 0.8399 | 0.7803 +- 0.0778 | 0.8087 |
| glue | cola | Qwen/Qwen2.5-7B-Instruct | 0.6273 +- 0.2691 | 0.7569 | 0.7086 +- 0.1239 | 0.7789 | 0.6428 +- 0.2337 | 0.7635 |
| glue | cola | Qwen/Qwen3-1.7B | 0.6827 +- 0.0442 | 0.6837 | 0.7047 +- 0.0528 | 0.7133 | 0.6656 +- 0.0763 | 0.6651 |
| glue | cola | Qwen/Qwen3-14B | 0.7846 +- 0.0161 | 0.7753 | 0.8089 +- 0.0264 | 0.8144 | 0.7901 +- 0.0200 | 0.7843 |
| glue | cola | Qwen/Qwen3-30B-A3B | 0.7962 +- 0.0172 | 0.8047 | 0.7979 +- 0.0444 | 0.8260 | 0.7945 +- 0.0323 | 0.8132 |
| glue | cola | Qwen/Qwen3-32B | 0.7460 +- 0.0414 | 0.7673 | 0.7828 +- 0.0463 | 0.8084 | 0.7487 +- 0.0447 | 0.7722 |
| glue | cola | Qwen/Qwen3-8B | 0.7573 +- 0.0508 | 0.7773 | 0.7640 +- 0.0469 | 0.7892 | 0.7542 +- 0.0560 | 0.7866 |
| glue | cola | Qwen/Qwen3.5-2B | 0.6019 +- 0.0531 | 0.6031 | 0.6157 +- 0.0582 | 0.6196 | 0.5878 +- 0.0657 | 0.5746 |
| glue | cola | Qwen/Qwen3.5-9B | 0.6409 +- 0.0520 | 0.6574 | 0.6635 +- 0.0617 | 0.6838 | 0.6359 +- 0.0517 | 0.6505 |
| glue | cola | google/gemma-2-9b-it | 0.7774 +- 0.0349 | 0.7831 | 0.7727 +- 0.0576 | 0.7951 | 0.7714 +- 0.0472 | 0.7924 |
| glue | cola | google/gemma-4-26B-A4B-it | 0.7130 +- 0.1558 | 0.8099 | 0.7006 +- 0.1401 | 0.7974 | 0.7002 +- 0.1535 | 0.8030 |
| glue | cola | google/gemma-4-31B-it | 0.8111 +- 0.0589 | 0.8371 | 0.7693 +- 0.0979 | 0.8234 | 0.7777 +- 0.0965 | 0.8296 |
| glue | cola | meta-llama/Meta-Llama-3-8B-Instruct | 0.7380 +- 0.0334 | 0.7372 | 0.7389 +- 0.0495 | 0.7649 | 0.7330 +- 0.0434 | 0.7445 |
There are two takeaways here:
- some models are more resilient to prompt changes
- most prompts performed similarly, but some prompts are significantly worse than others
For our purposes of comparing prompting and finetuning, let’s just assume that when crafting a prompt we luck out and get the best or one of the better prompts.
1.2.1 Does aggregation improve prompting?
If you’ve ever tried using prompting to classify you’ll understand the frustration of dealing with the randomness of the decoding process. There’s nothing quite as fun as end users telling you your “model” isn’t consistent.
To tackle this I often aggregate (using polling) multiple runs. It’s a relatively straightforward way of reducing variability in outputs and getting a confidence for a given answer. I’m aware of logit probs, but I think a lot is left on the table when doing this (a discussion for another time).
To see if aggregation helps, experiments across different n choose k were conducted. Below are the results:

Aggregation metrics summary statistics
| dataset_name | subset_name | model_plot_label | pooled_k | macro_precision_mean_std | macro_precision_median | macro_recall_mean_std | macro_recall_median | macro_f1_mean_std | macro_f1_median |
|---|---|---|---|---|---|---|---|---|---|
| glue | cola | Meta-Llama-3-8B-Instruct | 2 | 0.7385 +- 0.0014 | 0.7378 | 0.7396 +- 0.0011 | 0.7393 | 0.7339 +- 0.0011 | 0.7337 |
| glue | cola | Meta-Llama-3-8B-Instruct | 3 | 0.7468 +- 0.0027 | 0.7465 | 0.7451 +- 0.0020 | 0.7452 | 0.7401 +- 0.0021 | 0.7403 |
| glue | cola | Meta-Llama-3-8B-Instruct | 4 | 0.7478 +- 0.0039 | 0.7484 | 0.7461 +- 0.0035 | 0.7471 | 0.7414 +- 0.0038 | 0.7428 |
| glue | cola | Meta-Llama-3-8B-Instruct | 5 | 0.7491 +- 0.0025 | 0.7492 | 0.7461 +- 0.0034 | 0.7476 | 0.7420 +- 0.0031 | 0.7433 |
| glue | cola | Meta-Llama-3-8B-Instruct | 6 | 0.7509 +- 0.0023 | 0.7503 | 0.7480 +- 0.0022 | 0.7474 | 0.7438 +- 0.0022 | 0.7432 |
| glue | cola | Meta-Llama-3-8B-Instruct | 7 | 0.7520 +- 0.0024 | 0.7518 | 0.7483 +- 0.0021 | 0.7488 | 0.7442 +- 0.0022 | 0.7441 |
| glue | cola | Meta-Llama-3-8B-Instruct | 8 | 0.7529 +- 0.0021 | 0.7535 | 0.7493 +- 0.0018 | 0.7495 | 0.7452 +- 0.0018 | 0.7456 |
| glue | cola | Meta-Llama-3-8B-Instruct | 9 | 0.7522 +- 0.0016 | 0.7519 | 0.7483 +- 0.0015 | 0.7481 | 0.7444 +- 0.0016 | 0.7440 |
| glue | cola | Qwen1.5-7B-Chat | 2 | 0.7484 +- 0.0024 | 0.7500 | 0.7141 +- 0.0025 | 0.7146 | 0.7258 +- 0.0025 | 0.7262 |
| glue | cola | Qwen1.5-7B-Chat | 3 | 0.7566 +- 0.0018 | 0.7571 | 0.7183 +- 0.0019 | 0.7182 | 0.7311 +- 0.0019 | 0.7312 |
| glue | cola | Qwen1.5-7B-Chat | 4 | 0.7586 +- 0.0021 | 0.7584 | 0.7199 +- 0.0022 | 0.7197 | 0.7327 +- 0.0022 | 0.7325 |
| glue | cola | Qwen1.5-7B-Chat | 5 | 0.7609 +- 0.0016 | 0.7608 | 0.7204 +- 0.0017 | 0.7202 | 0.7337 +- 0.0017 | 0.7334 |
| glue | cola | Qwen1.5-7B-Chat | 6 | 0.7613 +- 0.0012 | 0.7612 | 0.7214 +- 0.0011 | 0.7216 | 0.7346 +- 0.0011 | 0.7347 |
| glue | cola | Qwen1.5-7B-Chat | 7 | 0.7616 +- 0.0016 | 0.7616 | 0.7204 +- 0.0016 | 0.7208 | 0.7338 +- 0.0017 | 0.7341 |
| glue | cola | Qwen1.5-7B-Chat | 8 | 0.7624 +- 0.0014 | 0.7627 | 0.7215 +- 0.0015 | 0.7218 | 0.7349 +- 0.0015 | 0.7354 |
| glue | cola | Qwen1.5-7B-Chat | 9 | 0.7617 +- 0.0012 | 0.7616 | 0.7199 +- 0.0013 | 0.7199 | 0.7334 +- 0.0013 | 0.7334 |
| glue | cola | Qwen2-7B-Instruct | 2 | 0.7692 +- 0.0040 | 0.7716 | 0.7053 +- 0.0030 | 0.7050 | 0.7196 +- 0.0031 | 0.7195 |
| glue | cola | Qwen2-7B-Instruct | 3 | 0.7843 +- 0.0054 | 0.7851 | 0.7096 +- 0.0049 | 0.7091 | 0.7253 +- 0.0055 | 0.7250 |
| glue | cola | Qwen2-7B-Instruct | 4 | 0.7854 +- 0.0038 | 0.7858 | 0.7109 +- 0.0048 | 0.7114 | 0.7266 +- 0.0051 | 0.7271 |
| glue | cola | Qwen2-7B-Instruct | 5 | 0.7861 +- 0.0046 | 0.7854 | 0.7098 +- 0.0035 | 0.7095 | 0.7255 +- 0.0040 | 0.7252 |
| glue | cola | Qwen2-7B-Instruct | 6 | 0.7889 +- 0.0033 | 0.7896 | 0.7131 +- 0.0025 | 0.7132 | 0.7289 +- 0.0028 | 0.7290 |
| glue | cola | Qwen2-7B-Instruct | 7 | 0.7903 +- 0.0031 | 0.7907 | 0.7129 +- 0.0029 | 0.7133 | 0.7290 +- 0.0033 | 0.7296 |
| glue | cola | Qwen2-7B-Instruct | 8 | 0.7906 +- 0.0019 | 0.7903 | 0.7121 +- 0.0015 | 0.7120 | 0.7281 +- 0.0017 | 0.7282 |
| glue | cola | Qwen2-7B-Instruct | 9 | 0.7926 +- 0.0022 | 0.7917 | 0.7128 +- 0.0018 | 0.7124 | 0.7292 +- 0.0021 | 0.7288 |
| glue | cola | Qwen2.5-1.5B-Instruct | 2 | 0.5789 +- 0.0046 | 0.5802 | 0.5804 +- 0.0047 | 0.5824 | 0.5355 +- 0.0054 | 0.5388 |
| glue | cola | Qwen2.5-1.5B-Instruct | 3 | 0.6007 +- 0.0062 | 0.6019 | 0.5974 +- 0.0056 | 0.5984 | 0.5401 +- 0.0058 | 0.5401 |
| glue | cola | Qwen2.5-1.5B-Instruct | 4 | 0.6010 +- 0.0053 | 0.6013 | 0.5962 +- 0.0041 | 0.5970 | 0.5379 +- 0.0036 | 0.5370 |
| glue | cola | Qwen2.5-1.5B-Instruct | 5 | 0.6135 +- 0.0026 | 0.6135 | 0.6043 +- 0.0026 | 0.6036 | 0.5389 +- 0.0035 | 0.5381 |
| glue | cola | Qwen2.5-1.5B-Instruct | 6 | 0.6143 +- 0.0050 | 0.6138 | 0.6051 +- 0.0038 | 0.6056 | 0.5395 +- 0.0041 | 0.5399 |
| glue | cola | Qwen2.5-1.5B-Instruct | 7 | 0.6251 +- 0.0057 | 0.6244 | 0.6106 +- 0.0029 | 0.6094 | 0.5402 +- 0.0031 | 0.5398 |
| glue | cola | Qwen2.5-1.5B-Instruct | 8 | 0.6270 +- 0.0038 | 0.6280 | 0.6120 +- 0.0024 | 0.6118 | 0.5420 +- 0.0030 | 0.5416 |
| glue | cola | Qwen2.5-1.5B-Instruct | 9 | 0.6323 +- 0.0033 | 0.6329 | 0.6151 +- 0.0013 | 0.6151 | 0.5420 +- 0.0014 | 0.5419 |
| glue | cola | Qwen2.5-14B-Instruct | 2 | 0.7451 +- 0.0031 | 0.7453 | 0.7677 +- 0.0029 | 0.7674 | 0.7307 +- 0.0022 | 0.7305 |
| glue | cola | Qwen2.5-14B-Instruct | 3 | 0.7503 +- 0.0030 | 0.7507 | 0.7727 +- 0.0029 | 0.7730 | 0.7340 +- 0.0027 | 0.7344 |
| glue | cola | Qwen2.5-14B-Instruct | 4 | 0.7503 +- 0.0020 | 0.7499 | 0.7724 +- 0.0018 | 0.7717 | 0.7330 +- 0.0015 | 0.7327 |
| glue | cola | Qwen2.5-14B-Instruct | 5 | 0.7500 +- 0.0019 | 0.7500 | 0.7720 +- 0.0018 | 0.7719 | 0.7321 +- 0.0013 | 0.7319 |
| glue | cola | Qwen2.5-14B-Instruct | 6 | 0.7519 +- 0.0023 | 0.7524 | 0.7738 +- 0.0021 | 0.7741 | 0.7339 +- 0.0016 | 0.7339 |
| glue | cola | Qwen2.5-14B-Instruct | 7 | 0.7513 +- 0.0020 | 0.7515 | 0.7731 +- 0.0019 | 0.7731 | 0.7330 +- 0.0018 | 0.7335 |
| glue | cola | Qwen2.5-14B-Instruct | 8 | 0.7508 +- 0.0017 | 0.7509 | 0.7724 +- 0.0018 | 0.7725 | 0.7326 +- 0.0018 | 0.7328 |
| glue | cola | Qwen2.5-14B-Instruct | 9 | 0.7515 +- 0.0011 | 0.7515 | 0.7732 +- 0.0011 | 0.7732 | 0.7331 +- 0.0011 | 0.7331 |
| glue | cola | Qwen2.5-32B-Instruct | 2 | 0.7748 +- 0.0017 | 0.7755 | 0.7974 +- 0.0012 | 0.7979 | 0.7798 +- 0.0017 | 0.7804 |
| glue | cola | Qwen2.5-32B-Instruct | 3 | 0.7839 +- 0.0025 | 0.7841 | 0.8063 +- 0.0025 | 0.8063 | 0.7895 +- 0.0027 | 0.7898 |
| glue | cola | Qwen2.5-32B-Instruct | 4 | 0.7837 +- 0.0020 | 0.7827 | 0.8067 +- 0.0019 | 0.8061 | 0.7894 +- 0.0021 | 0.7884 |
| glue | cola | Qwen2.5-32B-Instruct | 5 | 0.7854 +- 0.0013 | 0.7855 | 0.8080 +- 0.0015 | 0.8081 | 0.7913 +- 0.0015 | 0.7914 |
| glue | cola | Qwen2.5-32B-Instruct | 6 | 0.7864 +- 0.0014 | 0.7865 | 0.8090 +- 0.0017 | 0.8094 | 0.7923 +- 0.0016 | 0.7924 |
| glue | cola | Qwen2.5-32B-Instruct | 7 | 0.7862 +- 0.0020 | 0.7871 | 0.8093 +- 0.0021 | 0.8099 | 0.7924 +- 0.0021 | 0.7931 |
| glue | cola | Qwen2.5-32B-Instruct | 8 | 0.7865 +- 0.0010 | 0.7864 | 0.8088 +- 0.0014 | 0.8087 | 0.7924 +- 0.0011 | 0.7923 |
| glue | cola | Qwen2.5-32B-Instruct | 9 | 0.7869 +- 0.0011 | 0.7869 | 0.8098 +- 0.0013 | 0.8098 | 0.7930 +- 0.0012 | 0.7929 |
| glue | cola | Qwen2.5-7B-Instruct | 2 | 0.6292 +- 0.0018 | 0.6289 | 0.7108 +- 0.0020 | 0.7106 | 0.6447 +- 0.0016 | 0.6443 |
| glue | cola | Qwen2.5-7B-Instruct | 3 | 0.6321 +- 0.0023 | 0.6317 | 0.7141 +- 0.0027 | 0.7139 | 0.6474 +- 0.0028 | 0.6467 |
| glue | cola | Qwen2.5-7B-Instruct | 4 | 0.6336 +- 0.0026 | 0.6334 | 0.7161 +- 0.0029 | 0.7161 | 0.6488 +- 0.0029 | 0.6485 |
| glue | cola | Qwen2.5-7B-Instruct | 5 | 0.6351 +- 0.0021 | 0.6345 | 0.7175 +- 0.0023 | 0.7166 | 0.6500 +- 0.0025 | 0.6494 |
| glue | cola | Qwen2.5-7B-Instruct | 6 | 0.6355 +- 0.0021 | 0.6359 | 0.7180 +- 0.0022 | 0.7184 | 0.6507 +- 0.0023 | 0.6510 |
| glue | cola | Qwen2.5-7B-Instruct | 7 | 0.6361 +- 0.0015 | 0.6364 | 0.7185 +- 0.0017 | 0.7190 | 0.6512 +- 0.0017 | 0.6515 |
| glue | cola | Qwen2.5-7B-Instruct | 8 | 0.6366 +- 0.0011 | 0.6370 | 0.7193 +- 0.0011 | 0.7197 | 0.6517 +- 0.0011 | 0.6519 |
| glue | cola | Qwen2.5-7B-Instruct | 9 | 0.6370 +- 0.0011 | 0.6374 | 0.7195 +- 0.0012 | 0.7201 | 0.6519 +- 0.0011 | 0.6521 |
| glue | cola | Qwen3-1.7B | 2 | 0.6824 +- 0.0017 | 0.6826 | 0.7039 +- 0.0018 | 0.7036 | 0.6643 +- 0.0015 | 0.6639 |
| glue | cola | Qwen3-1.7B | 3 | 0.6888 +- 0.0025 | 0.6888 | 0.7101 +- 0.0029 | 0.7101 | 0.6684 +- 0.0032 | 0.6685 |
| glue | cola | Qwen3-1.7B | 4 | 0.6903 +- 0.0025 | 0.6896 | 0.7117 +- 0.0028 | 0.7111 | 0.6703 +- 0.0030 | 0.6698 |
| glue | cola | Qwen3-1.7B | 5 | 0.6912 +- 0.0017 | 0.6910 | 0.7122 +- 0.0019 | 0.7120 | 0.6702 +- 0.0021 | 0.6703 |
| glue | cola | Qwen3-1.7B | 6 | 0.6912 +- 0.0011 | 0.6913 | 0.7120 +- 0.0013 | 0.7123 | 0.6697 +- 0.0014 | 0.6696 |
| glue | cola | Qwen3-1.7B | 7 | 0.6918 +- 0.0014 | 0.6919 | 0.7126 +- 0.0016 | 0.7127 | 0.6702 +- 0.0018 | 0.6702 |
| glue | cola | Qwen3-1.7B | 8 | 0.6908 +- 0.0011 | 0.6913 | 0.7114 +- 0.0011 | 0.7118 | 0.6688 +- 0.0013 | 0.6691 |
| glue | cola | Qwen3-1.7B | 9 | 0.6924 +- 0.0009 | 0.6927 | 0.7130 +- 0.0008 | 0.7129 | 0.6703 +- 0.0009 | 0.6703 |
| glue | cola | Qwen3-14B | 2 | 0.7852 +- 0.0019 | 0.7848 | 0.8104 +- 0.0024 | 0.8119 | 0.7913 +- 0.0019 | 0.7917 |
| glue | cola | Qwen3-14B | 3 | 0.7988 +- 0.0020 | 0.7989 | 0.8221 +- 0.0019 | 0.8215 | 0.8040 +- 0.0020 | 0.8037 |
| glue | cola | Qwen3-14B | 4 | 0.7997 +- 0.0017 | 0.7996 | 0.8238 +- 0.0029 | 0.8247 | 0.8053 +- 0.0023 | 0.8059 |
| glue | cola | Qwen3-14B | 5 | 0.8025 +- 0.0025 | 0.8020 | 0.8254 +- 0.0026 | 0.8257 | 0.8077 +- 0.0025 | 0.8074 |
| glue | cola | Qwen3-14B | 6 | 0.8035 +- 0.0019 | 0.8032 | 0.8268 +- 0.0021 | 0.8271 | 0.8087 +- 0.0019 | 0.8089 |
| glue | cola | Qwen3-14B | 7 | 0.8049 +- 0.0021 | 0.8044 | 0.8274 +- 0.0022 | 0.8273 | 0.8099 +- 0.0023 | 0.8096 |
| glue | cola | Qwen3-14B | 8 | 0.8047 +- 0.0012 | 0.8044 | 0.8282 +- 0.0014 | 0.8280 | 0.8102 +- 0.0014 | 0.8098 |
| glue | cola | Qwen3-14B | 9 | 0.8051 +- 0.0013 | 0.8047 | 0.8279 +- 0.0010 | 0.8277 | 0.8103 +- 0.0012 | 0.8100 |
| glue | cola | Qwen3-30B-A3B | 2 | 0.7973 +- 0.0030 | 0.7992 | 0.7974 +- 0.0027 | 0.7985 | 0.7945 +- 0.0027 | 0.7957 |
| glue | cola | Qwen3-30B-A3B | 3 | 0.8050 +- 0.0020 | 0.8048 | 0.8030 +- 0.0018 | 0.8034 | 0.8008 +- 0.0018 | 0.8010 |
| glue | cola | Qwen3-30B-A3B | 4 | 0.8050 +- 0.0029 | 0.8055 | 0.8031 +- 0.0019 | 0.8034 | 0.8008 +- 0.0021 | 0.8007 |
| glue | cola | Qwen3-30B-A3B | 5 | 0.8051 +- 0.0015 | 0.8053 | 0.8025 +- 0.0017 | 0.8019 | 0.8005 +- 0.0016 | 0.8001 |
| glue | cola | Qwen3-30B-A3B | 6 | 0.8065 +- 0.0015 | 0.8058 | 0.8033 +- 0.0011 | 0.8028 | 0.8015 +- 0.0013 | 0.8010 |
| glue | cola | Qwen3-30B-A3B | 7 | 0.8070 +- 0.0013 | 0.8065 | 0.8049 +- 0.0015 | 0.8045 | 0.8028 +- 0.0014 | 0.8022 |
| glue | cola | Qwen3-30B-A3B | 8 | 0.8072 +- 0.0013 | 0.8070 | 0.8043 +- 0.0013 | 0.8042 | 0.8023 +- 0.0013 | 0.8022 |
| glue | cola | Qwen3-30B-A3B | 9 | 0.8066 +- 0.0009 | 0.8066 | 0.8042 +- 0.0008 | 0.8043 | 0.8022 +- 0.0008 | 0.8023 |
| glue | cola | Qwen3-32B | 2 | 0.7454 +- 0.0047 | 0.7478 | 0.7820 +- 0.0051 | 0.7844 | 0.7486 +- 0.0055 | 0.7511 |
| glue | cola | Qwen3-32B | 3 | 0.7668 +- 0.0021 | 0.7670 | 0.8044 +- 0.0023 | 0.8043 | 0.7725 +- 0.0025 | 0.7725 |
| glue | cola | Qwen3-32B | 4 | 0.7686 +- 0.0029 | 0.7684 | 0.8063 +- 0.0034 | 0.8060 | 0.7745 +- 0.0030 | 0.7749 |
| glue | cola | Qwen3-32B | 5 | 0.7727 +- 0.0030 | 0.7726 | 0.8103 +- 0.0034 | 0.8101 | 0.7789 +- 0.0033 | 0.7788 |
| glue | cola | Qwen3-32B | 6 | 0.7731 +- 0.0022 | 0.7735 | 0.8106 +- 0.0024 | 0.8109 | 0.7796 +- 0.0025 | 0.7801 |
| glue | cola | Qwen3-32B | 7 | 0.7766 +- 0.0020 | 0.7768 | 0.8143 +- 0.0023 | 0.8143 | 0.7832 +- 0.0021 | 0.7831 |
| glue | cola | Qwen3-32B | 8 | 0.7766 +- 0.0018 | 0.7759 | 0.8142 +- 0.0019 | 0.8137 | 0.7834 +- 0.0021 | 0.7827 |
| glue | cola | Qwen3-32B | 9 | 0.7795 +- 0.0011 | 0.7798 | 0.8173 +- 0.0011 | 0.8173 | 0.7863 +- 0.0012 | 0.7869 |
| glue | cola | Qwen3-8B | 2 | 0.7556 +- 0.0008 | 0.7554 | 0.7618 +- 0.0013 | 0.7614 | 0.7526 +- 0.0014 | 0.7528 |
| glue | cola | Qwen3-8B | 3 | 0.7657 +- 0.0032 | 0.7654 | 0.7703 +- 0.0033 | 0.7698 | 0.7621 +- 0.0032 | 0.7615 |
| glue | cola | Qwen3-8B | 4 | 0.7650 +- 0.0032 | 0.7654 | 0.7693 +- 0.0036 | 0.7697 | 0.7613 +- 0.0034 | 0.7617 |
| glue | cola | Qwen3-8B | 5 | 0.7665 +- 0.0029 | 0.7669 | 0.7703 +- 0.0028 | 0.7706 | 0.7627 +- 0.0031 | 0.7629 |
| glue | cola | Qwen3-8B | 6 | 0.7652 +- 0.0018 | 0.7653 | 0.7687 +- 0.0024 | 0.7691 | 0.7612 +- 0.0021 | 0.7615 |
| glue | cola | Qwen3-8B | 7 | 0.7682 +- 0.0028 | 0.7683 | 0.7716 +- 0.0028 | 0.7722 | 0.7640 +- 0.0026 | 0.7643 |
| glue | cola | Qwen3-8B | 8 | 0.7676 +- 0.0016 | 0.7671 | 0.7705 +- 0.0014 | 0.7703 | 0.7633 +- 0.0015 | 0.7628 |
| glue | cola | Qwen3-8B | 9 | 0.7683 +- 0.0015 | 0.7682 | 0.7711 +- 0.0015 | 0.7714 | 0.7639 +- 0.0014 | 0.7640 |
| glue | cola | Qwen3.5-2B | 2 | 0.6024 +- 0.0044 | 0.6001 | 0.6160 +- 0.0048 | 0.6131 | 0.5892 +- 0.0047 | 0.5876 |
| glue | cola | Qwen3.5-2B | 3 | 0.6295 +- 0.0026 | 0.6298 | 0.6456 +- 0.0029 | 0.6457 | 0.6147 +- 0.0027 | 0.6158 |
| glue | cola | Qwen3.5-2B | 4 | 0.6323 +- 0.0022 | 0.6317 | 0.6484 +- 0.0026 | 0.6476 | 0.6185 +- 0.0020 | 0.6179 |
| glue | cola | Qwen3.5-2B | 5 | 0.6463 +- 0.0019 | 0.6464 | 0.6637 +- 0.0021 | 0.6636 | 0.6306 +- 0.0027 | 0.6308 |
| glue | cola | Qwen3.5-2B | 6 | 0.6461 +- 0.0021 | 0.6454 | 0.6631 +- 0.0024 | 0.6627 | 0.6298 +- 0.0021 | 0.6297 |
| glue | cola | Qwen3.5-2B | 7 | 0.6544 +- 0.0033 | 0.6546 | 0.6720 +- 0.0040 | 0.6721 | 0.6382 +- 0.0036 | 0.6373 |
| glue | cola | Qwen3.5-2B | 8 | 0.6571 +- 0.0026 | 0.6572 | 0.6752 +- 0.0032 | 0.6756 | 0.6414 +- 0.0030 | 0.6413 |
| glue | cola | Qwen3.5-2B | 9 | 0.6602 +- 0.0014 | 0.6604 | 0.6783 +- 0.0016 | 0.6783 | 0.6436 +- 0.0016 | 0.6436 |
| glue | cola | Qwen3.5-9B | 2 | 0.6367 +- 0.0051 | 0.6354 | 0.6587 +- 0.0057 | 0.6573 | 0.6316 +- 0.0051 | 0.6298 |
| glue | cola | Qwen3.5-9B | 3 | 0.6796 +- 0.0058 | 0.6770 | 0.7068 +- 0.0065 | 0.7041 | 0.6783 +- 0.0063 | 0.6758 |
| glue | cola | Qwen3.5-9B | 4 | 0.6795 +- 0.0025 | 0.6793 | 0.7066 +- 0.0028 | 0.7066 | 0.6782 +- 0.0023 | 0.6780 |
| glue | cola | Qwen3.5-9B | 5 | 0.7001 +- 0.0037 | 0.7007 | 0.7283 +- 0.0041 | 0.7290 | 0.6994 +- 0.0042 | 0.6994 |
| glue | cola | Qwen3.5-9B | 6 | 0.6988 +- 0.0068 | 0.6986 | 0.7269 +- 0.0075 | 0.7264 | 0.6985 +- 0.0071 | 0.6979 |
| glue | cola | Qwen3.5-9B | 7 | 0.7145 +- 0.0028 | 0.7135 | 0.7425 +- 0.0030 | 0.7416 | 0.7141 +- 0.0027 | 0.7130 |
| glue | cola | Qwen3.5-9B | 8 | 0.7101 +- 0.0034 | 0.7102 | 0.7382 +- 0.0036 | 0.7376 | 0.7102 +- 0.0035 | 0.7106 |
| glue | cola | Qwen3.5-9B | 9 | 0.7229 +- 0.0024 | 0.7231 | 0.7503 +- 0.0022 | 0.7508 | 0.7224 +- 0.0023 | 0.7228 |
| glue | cola | gemma-2-9b-it | 2 | 0.7773 +- 0.0011 | 0.7771 | 0.7726 +- 0.0004 | 0.7724 | 0.7713 +- 0.0005 | 0.7711 |
| glue | cola | gemma-2-9b-it | 3 | 0.7794 +- 0.0013 | 0.7788 | 0.7736 +- 0.0008 | 0.7736 | 0.7724 +- 0.0009 | 0.7722 |
| glue | cola | gemma-2-9b-it | 4 | 0.7786 +- 0.0013 | 0.7786 | 0.7732 +- 0.0007 | 0.7731 | 0.7720 +- 0.0008 | 0.7718 |
| glue | cola | gemma-2-9b-it | 5 | 0.7799 +- 0.0018 | 0.7799 | 0.7739 +- 0.0012 | 0.7735 | 0.7727 +- 0.0014 | 0.7723 |
| glue | cola | gemma-2-9b-it | 6 | 0.7804 +- 0.0012 | 0.7806 | 0.7740 +- 0.0011 | 0.7742 | 0.7729 +- 0.0011 | 0.7732 |
| glue | cola | gemma-2-9b-it | 7 | 0.7809 +- 0.0011 | 0.7807 | 0.7744 +- 0.0008 | 0.7745 | 0.7734 +- 0.0008 | 0.7734 |
| glue | cola | gemma-2-9b-it | 8 | 0.7806 +- 0.0012 | 0.7802 | 0.7743 +- 0.0007 | 0.7743 | 0.7731 +- 0.0008 | 0.7731 |
| glue | cola | gemma-2-9b-it | 9 | 0.7815 +- 0.0009 | 0.7814 | 0.7751 +- 0.0008 | 0.7752 | 0.7741 +- 0.0008 | 0.7741 |
| glue | cola | gemma-4-26B-A4B-it | 2 | 0.7140 +- 0.0006 | 0.7138 | 0.7026 +- 0.0017 | 0.7031 | 0.7021 +- 0.0014 | 0.7029 |
| glue | cola | gemma-4-26B-A4B-it | 3 | 0.7201 +- 0.0030 | 0.7205 | 0.7086 +- 0.0028 | 0.7089 | 0.7070 +- 0.0033 | 0.7070 |
| glue | cola | gemma-4-26B-A4B-it | 4 | 0.7190 +- 0.0028 | 0.7184 | 0.7076 +- 0.0035 | 0.7067 | 0.7061 +- 0.0032 | 0.7053 |
| glue | cola | gemma-4-26B-A4B-it | 5 | 0.7252 +- 0.0022 | 0.7250 | 0.7136 +- 0.0020 | 0.7135 | 0.7115 +- 0.0021 | 0.7116 |
| glue | cola | gemma-4-26B-A4B-it | 6 | 0.7219 +- 0.0030 | 0.7211 | 0.7107 +- 0.0031 | 0.7103 | 0.7084 +- 0.0029 | 0.7079 |
| glue | cola | gemma-4-26B-A4B-it | 7 | 0.7260 +- 0.0036 | 0.7259 | 0.7144 +- 0.0032 | 0.7147 | 0.7112 +- 0.0032 | 0.7117 |
| glue | cola | gemma-4-26B-A4B-it | 8 | 0.7249 +- 0.0034 | 0.7248 | 0.7139 +- 0.0031 | 0.7138 | 0.7111 +- 0.0030 | 0.7111 |
| glue | cola | gemma-4-26B-A4B-it | 9 | 0.7292 +- 0.0026 | 0.7289 | 0.7175 +- 0.0023 | 0.7169 | 0.7139 +- 0.0022 | 0.7137 |
| glue | cola | gemma-4-31B-it | 2 | 0.8126 +- 0.0041 | 0.8143 | 0.7705 +- 0.0033 | 0.7717 | 0.7790 +- 0.0038 | 0.7800 |
| glue | cola | gemma-4-31B-it | 3 | 0.8289 +- 0.0022 | 0.8292 | 0.7731 +- 0.0025 | 0.7743 | 0.7822 +- 0.0028 | 0.7831 |
| glue | cola | gemma-4-31B-it | 4 | 0.8279 +- 0.0024 | 0.8273 | 0.7725 +- 0.0016 | 0.7719 | 0.7814 +- 0.0019 | 0.7811 |
| glue | cola | gemma-4-31B-it | 5 | 0.8305 +- 0.0027 | 0.8299 | 0.7723 +- 0.0019 | 0.7721 | 0.7812 +- 0.0023 | 0.7811 |
| glue | cola | gemma-4-31B-it | 6 | 0.8307 +- 0.0024 | 0.8307 | 0.7724 +- 0.0016 | 0.7723 | 0.7811 +- 0.0019 | 0.7810 |
| glue | cola | gemma-4-31B-it | 7 | 0.8332 +- 0.0018 | 0.8328 | 0.7735 +- 0.0015 | 0.7740 | 0.7824 +- 0.0017 | 0.7828 |
| glue | cola | gemma-4-31B-it | 8 | 0.8338 +- 0.0022 | 0.8337 | 0.7733 +- 0.0017 | 0.7731 | 0.7824 +- 0.0020 | 0.7821 |
| glue | cola | gemma-4-31B-it | 9 | 0.8342 +- 0.0009 | 0.8344 | 0.7738 +- 0.0008 | 0.7739 | 0.7828 +- 0.0009 | 0.7829 |
While aggregation can improve weaker or noisier prompted setups, in general stronger models don’t seem to benefit from this. This tool may be useful for more complex tasks, so it’s worth keeping in mind. For this specific experiment, we will ignore aggregation for the final comparison.
1.3.1 How does model family affect prompting performance?
This result is a subset of the overall experiment. Similar generation and size models were taken as stand ins for their respective “model families”. Llama3 8B, qwen2.5 7B, Gemma 2 9B models were used.
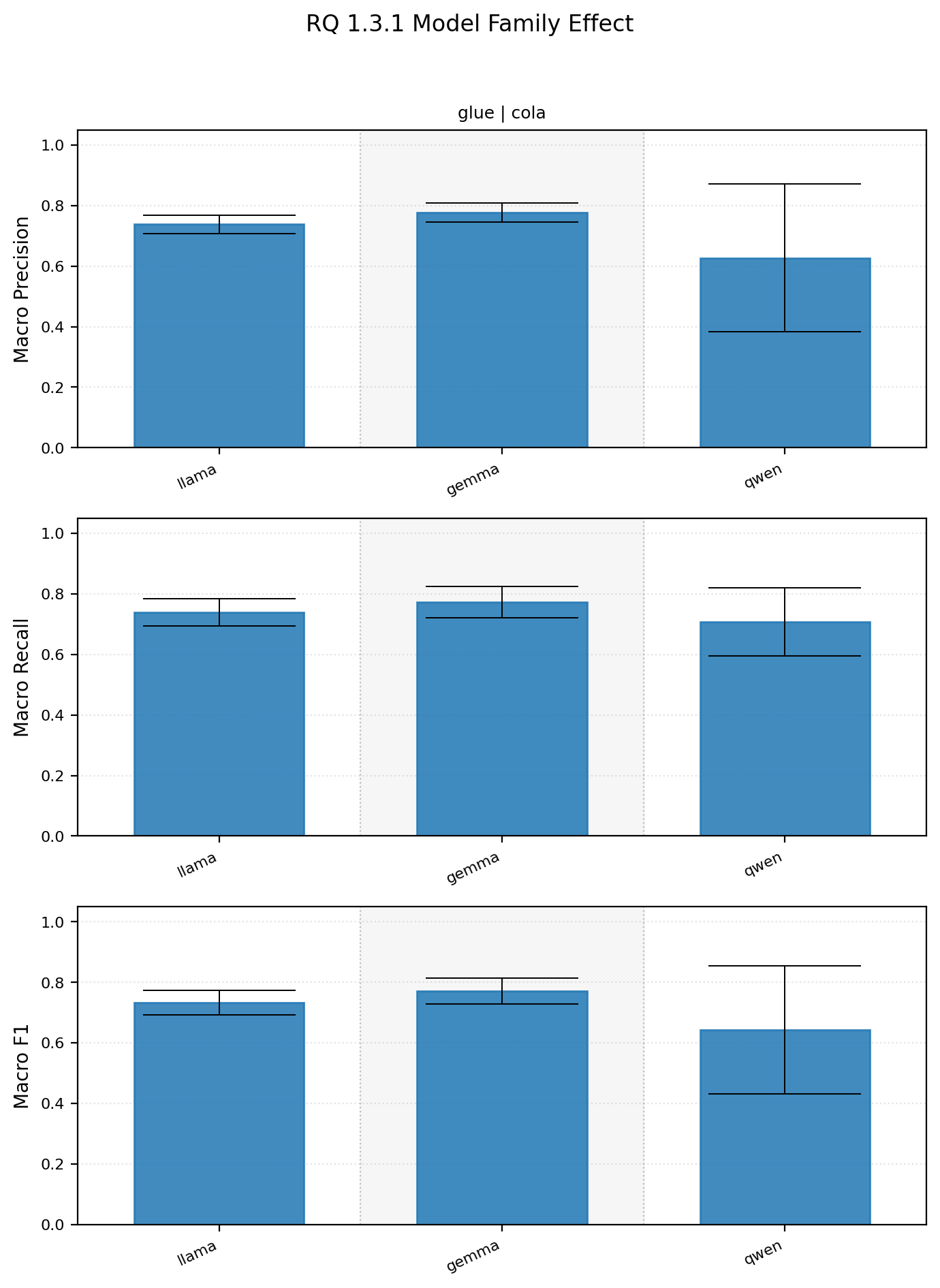
Model family summary statistics
| dataset_name | subset_name | model_family | macro_precision_mean_std | macro_precision_median | macro_recall_mean_std | macro_recall_median | macro_f1_mean_std | macro_f1_median |
|---|---|---|---|---|---|---|---|---|
| glue | cola | gemma | 0.7774 +- 0.0321 | 0.7825 | 0.7727 +- 0.0523 | 0.7957 | 0.7714 +- 0.0429 | 0.7918 |
| glue | cola | llama | 0.7380 +- 0.0312 | 0.7373 | 0.7389 +- 0.0454 | 0.7615 | 0.7330 +- 0.0399 | 0.7443 |
| glue | cola | qwen | 0.6273 +- 0.2433 | 0.7572 | 0.7086 +- 0.1123 | 0.7761 | 0.6428 +- 0.2113 | 0.7640 |
Based on this experiment model family does appear to matter, but in hindsight I think the underlying approach may be deeply flawed. Only 3 models were used, they were released around similar times, but that’s not exactly the case. I also couldn’t really account for other variables such as model size or generation since it’s hard to find 1 to 1 equivalence between model families. I think a multivariate analysis might make more sense in the future, but some thought needs to be put into how to properly conduct that.
1.3.2 How does model size affect prompting performance?
A similar approach to 1.3.1 was used to account for model size. Performance between different sizes of the Qwen 2.5 series was swept across. Spoiler, bigger prompted models do better in the Qwen 2.5 size sweep.
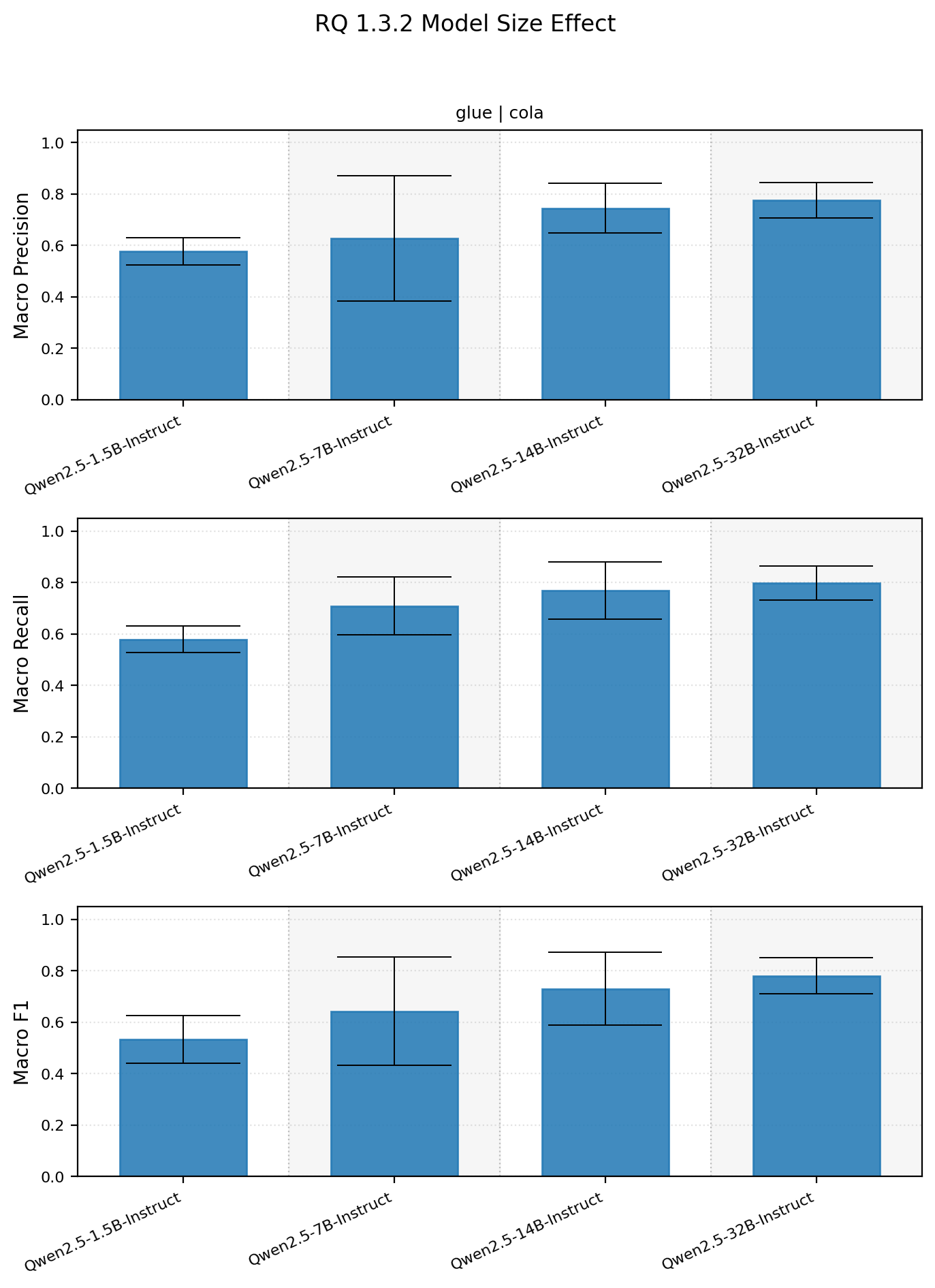
Model size summary statistics
| dataset_name | subset_name | model_name | macro_precision_mean_std | macro_precision_median | macro_recall_mean_std | macro_recall_median | macro_f1_mean_std | macro_f1_median |
|---|---|---|---|---|---|---|---|---|
| glue | cola | Qwen/Qwen2.5-1.5B-Instruct | 0.5770 +- 0.0529 | 0.5734 | 0.5788 +- 0.0511 | 0.5829 | 0.5339 +- 0.0926 | 0.5689 |
| glue | cola | Qwen/Qwen2.5-14B-Instruct | 0.7447 +- 0.0966 | 0.7874 | 0.7675 +- 0.1110 | 0.8281 | 0.7303 +- 0.1424 | 0.7948 |
| glue | cola | Qwen/Qwen2.5-32B-Instruct | 0.7753 +- 0.0689 | 0.7996 | 0.7980 +- 0.0660 | 0.8371 | 0.7803 +- 0.0706 | 0.8089 |
| glue | cola | Qwen/Qwen2.5-7B-Instruct | 0.6273 +- 0.2433 | 0.7572 | 0.7086 +- 0.1123 | 0.7761 | 0.6428 +- 0.2113 | 0.7640 |
Model performance does seem to keep increasing as a function of size. In future results I think testing larger models might be important to find where the limit of prompting, if one exists, is.
1.3.3 How do MoEs compare to dense models?
Ok for MoE vs dense comparison I decided to use 2 model familes with 30B models. Given that there are only 4 models the results are pretty inconclusive.
Looking at the initial results, which all models performed well, gemma-4-26B-A4B struggled on some prompts lower its average performance. For the Qwen models the MOE appears to do better, but its the opposite for Gemma.
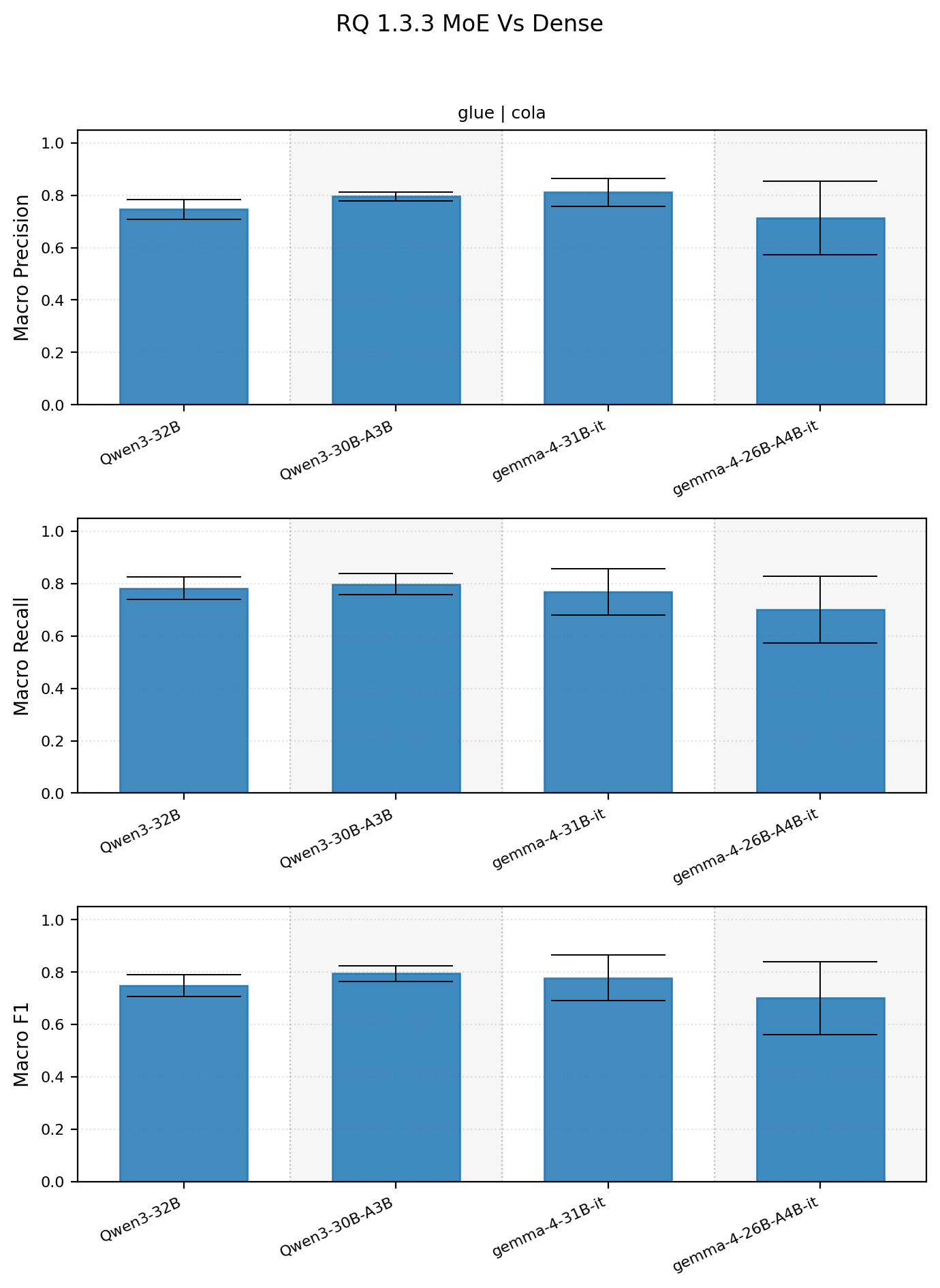
Dense versus MoE summary statistics
| dataset_name | subset_name | model_name | macro_precision_mean_std | macro_precision_median | macro_recall_mean_std | macro_recall_median | macro_f1_mean_std | macro_f1_median |
|---|---|---|---|---|---|---|---|---|
| glue | cola | Qwen/Qwen3-30B-A3B | 0.7962 +- 0.0169 | 0.8031 | 0.7979 +- 0.0405 | 0.8234 | 0.7945 +- 0.0298 | 0.8115 |
| glue | cola | Qwen/Qwen3-32B | 0.7460 +- 0.0381 | 0.7649 | 0.7828 +- 0.0426 | 0.8067 | 0.7487 +- 0.0411 | 0.7668 |
| glue | cola | google/gemma-4-26B-A4B-it | 0.7130 +- 0.1410 | 0.8096 | 0.7006 +- 0.1269 | 0.7955 | 0.7002 +- 0.1389 | 0.8017 |
| glue | cola | google/gemma-4-31B-it | 0.8111 +- 0.0539 | 0.8362 | 0.7693 +- 0.0887 | 0.8234 | 0.7777 +- 0.0875 | 0.8292 |
For now lets consider this analysis a wash and come back to it later.
2.2 How does model size affect finetuning?
Alright, we’ve analyzed prompting to death. How does finetuning do? Pretty well actually.
Finetuned encoder size also matters, and the curve is stronger than the prompted runs might make you expect.
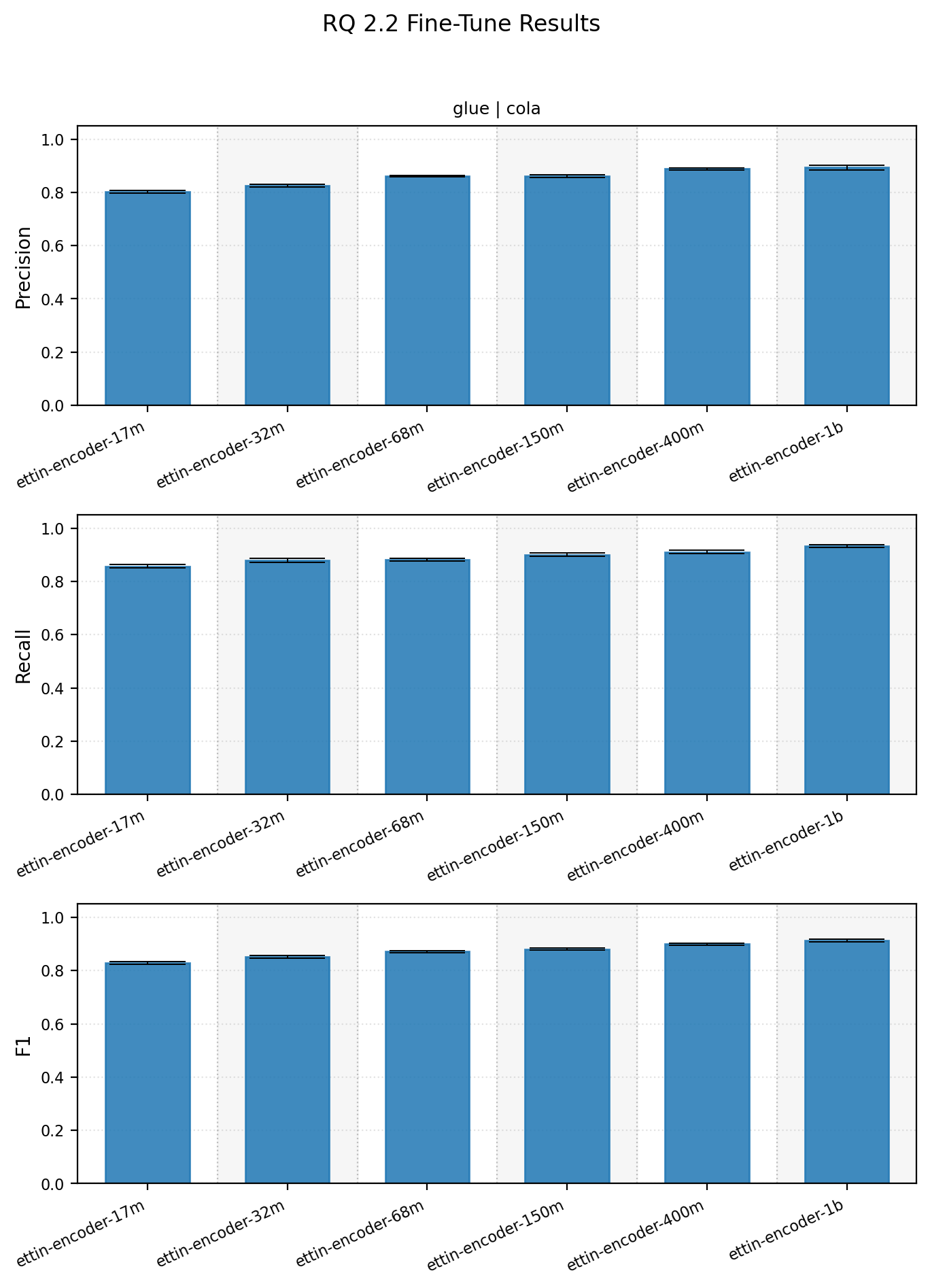
Finetuning summary statistics
| dataset | subset | model_name | eval_precision_mean_std | eval_precision_median | eval_recall_mean_std | eval_recall_median | eval_f1_mean_std | eval_f1_median |
|---|---|---|---|---|---|---|---|---|
| glue | cola | ettin-encoder-150m | 0.8607 +- 0.0045 | 0.8605 | 0.9004 +- 0.0066 | 0.8994 | 0.8801 +- 0.0038 | 0.8807 |
| glue | cola | ettin-encoder-17m | 0.8029 +- 0.0047 | 0.8022 | 0.8570 +- 0.0060 | 0.8564 | 0.8291 +- 0.0044 | 0.8292 |
| glue | cola | ettin-encoder-1b | 0.8930 +- 0.0087 | 0.8906 | 0.9333 +- 0.0049 | 0.9341 | 0.9127 +- 0.0042 | 0.9125 |
| glue | cola | ettin-encoder-32m | 0.8259 +- 0.0054 | 0.8264 | 0.8791 +- 0.0084 | 0.8807 | 0.8516 +- 0.0049 | 0.8521 |
| glue | cola | ettin-encoder-400m | 0.8878 +- 0.0045 | 0.8874 | 0.9110 +- 0.0058 | 0.9092 | 0.8992 +- 0.0032 | 0.8992 |
| glue | cola | ettin-encoder-68m | 0.8608 +- 0.0032 | 0.8624 | 0.8810 +- 0.0056 | 0.8793 | 0.8708 +- 0.0030 | 0.8703 |
The takeaway here is that even the smallest finetuned encoder is competitive with strong prompted decoders, and the larger finetuned encoders move clearly past them on this task.
3.2 Ok,so how do finetuning and prompting compare?
We can make an initial comparison with the data at hand.
Given the nature of the claim about larger prompt-based models being better, I’m going to steelman the argument by comparing the strongest possible
prompt.
The strongest prompted result is google/gemma-4-31B-it with Make sense yes no, at 0.8479 +- 0.0052 macro F1.
The result here isn’t too surprising, we have
- a latest generation model
- large model
- dense model
- from a strong family
- with a good prompt
- didn’t need aggregation
ettin-encoder-17m reaches 0.8291 +- 0.0044, which is already competitive with prompting approaches. The 32m encoder is at 0.8516 +- 0.0049, roughly matching or slightly beating the best prompted result.
On average across prompts, google/gemma-4-31B-it is closer to 0.7777 +- 0.0965 macro F1. In practice, we usually will not have enough budget to run this many prompt/model combinations without overfitting to the validation set.
In this context the finetuned encoders seem to have a leg up.
So What?
Given the caveats above, this is not enough to make a definitive conclusion. That said, these early results do push against the narrative that prompting is inherently superior. My current suspicion is that this trend will persist across additional datasets, and that finetuning will often provide better classification performance at much smaller model sizes. Given the cost of generation, especially multi-token generation if creating a rationale, having cheaper faster models for classification has obvious implications. If a 32M model can match a 32B one (three orders of magnitude larger), that opens up the door for larger scale processing. 32M is small enough that this can run very quickly on a CPU only machine or in very large batches on GPU machines.
Next post aims to expand the scope and see if the trends observed above hold across different datasets.
- Extend to other classification datasets (e.g., NLI)
- Improve speed for experiments, currently the prompting experiments are running very slowly
- Explore additional RQs
- 1.2
- 1.3
- 2.1
- 2.3
- 3.1
- Rework 1.3 analyses to better account for multivariate nature of comparisons rather than using “tracks”